
Sitemap
A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Pages
Data Retention Policies
Published in Policies, 2024
Establish clear policies for how long data should be retained based on regulatory requirements and business needs.
My Master Data Management Reference Architecture
Published in Master Data, 2024
Leverage Business Capability Maps for Data Domains
Data Strategy and architecture in practice
Published:
Please Read Carefully
Published:
Solve technical problems, increase efficiency and productivity, and improve systems </a> </h2> </article> </div>Posts
Hello PyTorch
Published:
The objective is to use the very basic example of linear regression and use PyTorch to build a model to demonstrate Pytorch workflow and its fundementals.
SpaceTitanic Pipeline - Model Impute - 81 score
Published:
The objective in this Notebook is to use a Pipeline to streamline development of code. I will not be focusing on data analysis and charts.
Machine Learning for daily tasks
Published:
I was tasked with planning demand for tickets for a complex Application Maintenance System that supports multiple companies. There was some historical data available, and it was invaluable. Using machine learning with sklearn, we were able to predict ticket volumes on a monthly basis with a very high degree of accuracy. Going through the usecase
Blog Post number 3
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
portfolio
What is it that we want from our data architecture
This is the dream: We strive for a unified and usable data and analytic platform
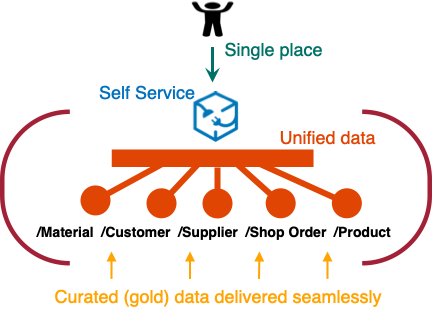
What is unified data
A single, coherent, and consistent view of the data across the organization
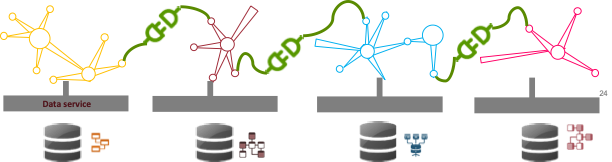
Integrated Data
Combining data from different sources and providing a unified view
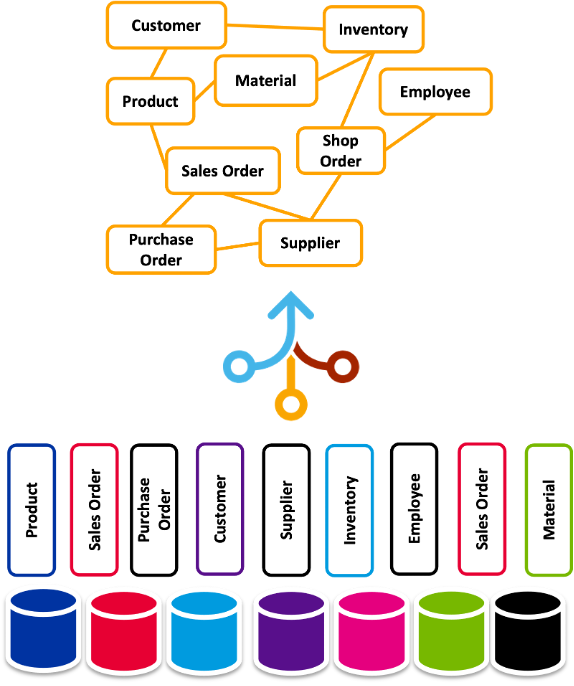
What is usable data
We need data to have an acceptable quality, readily available and easily accessible.

Data Governance
We want the data to be usable. How do we ensure it?

Data Management
Making Data Useful and Integrated:

Collect Architecture
Collect the data for analytics:

Curate Architecture
Curate the data for analytics:

Storage Architecture
Storage for Data Analytics: Coming Soon

Data Analytics Architectures
A Brief History
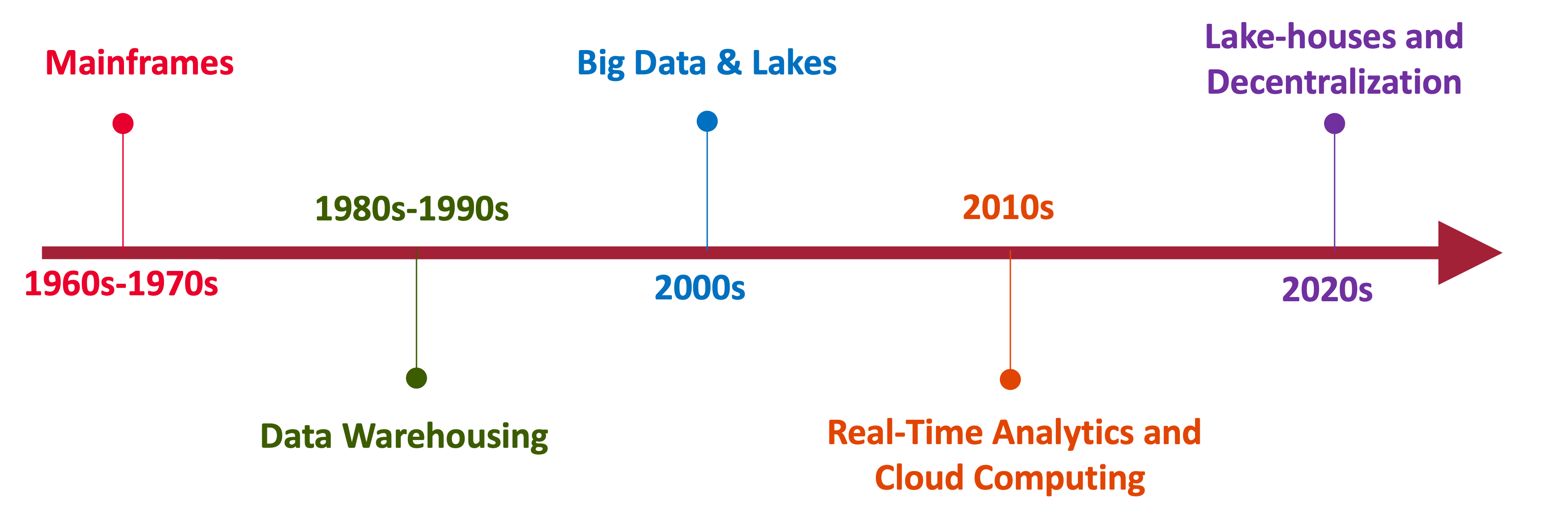
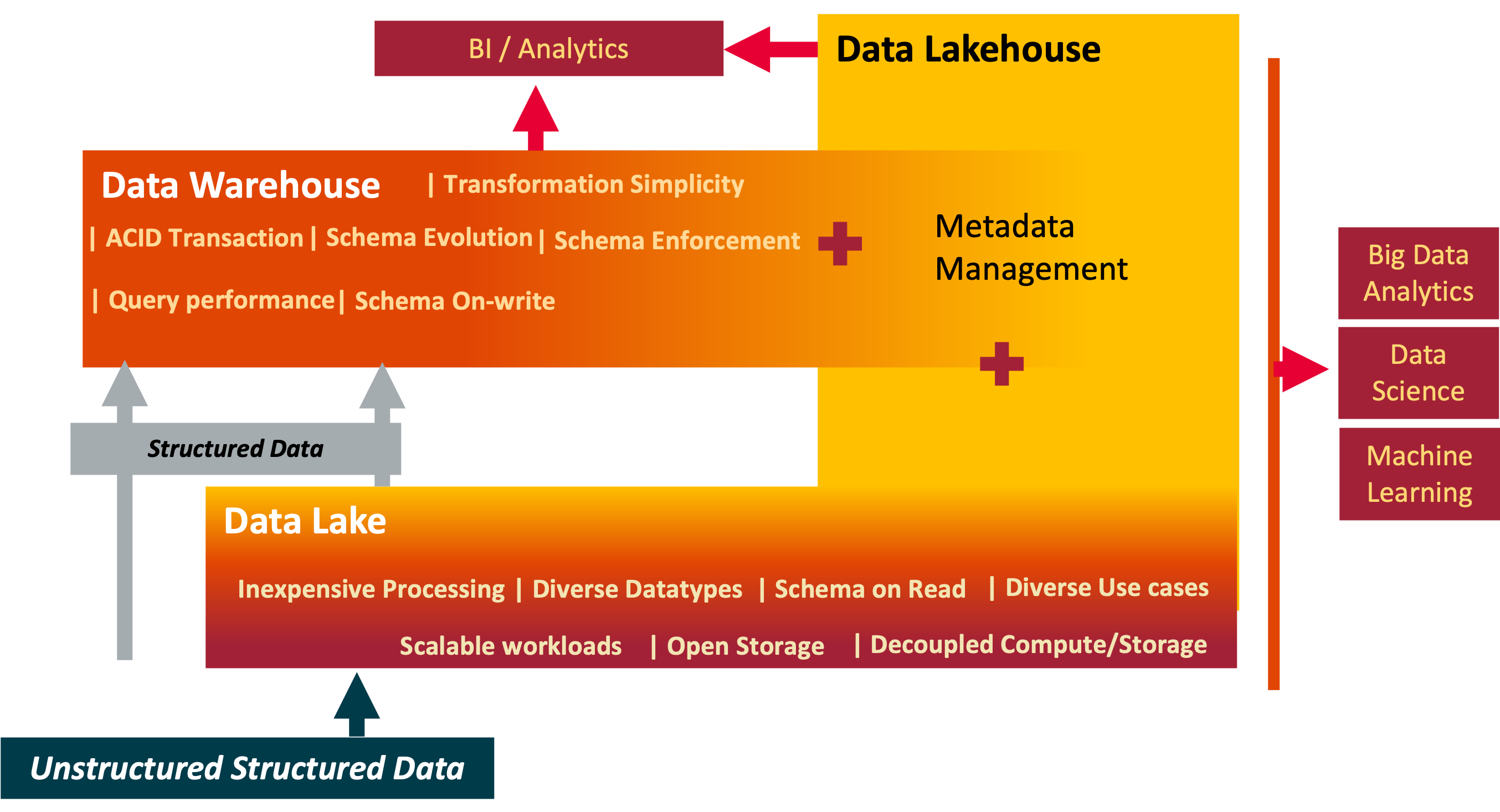
Data: Warehouse, Lake and Lakehouse
Yesterday, Today and Tomorrow of Data Processing
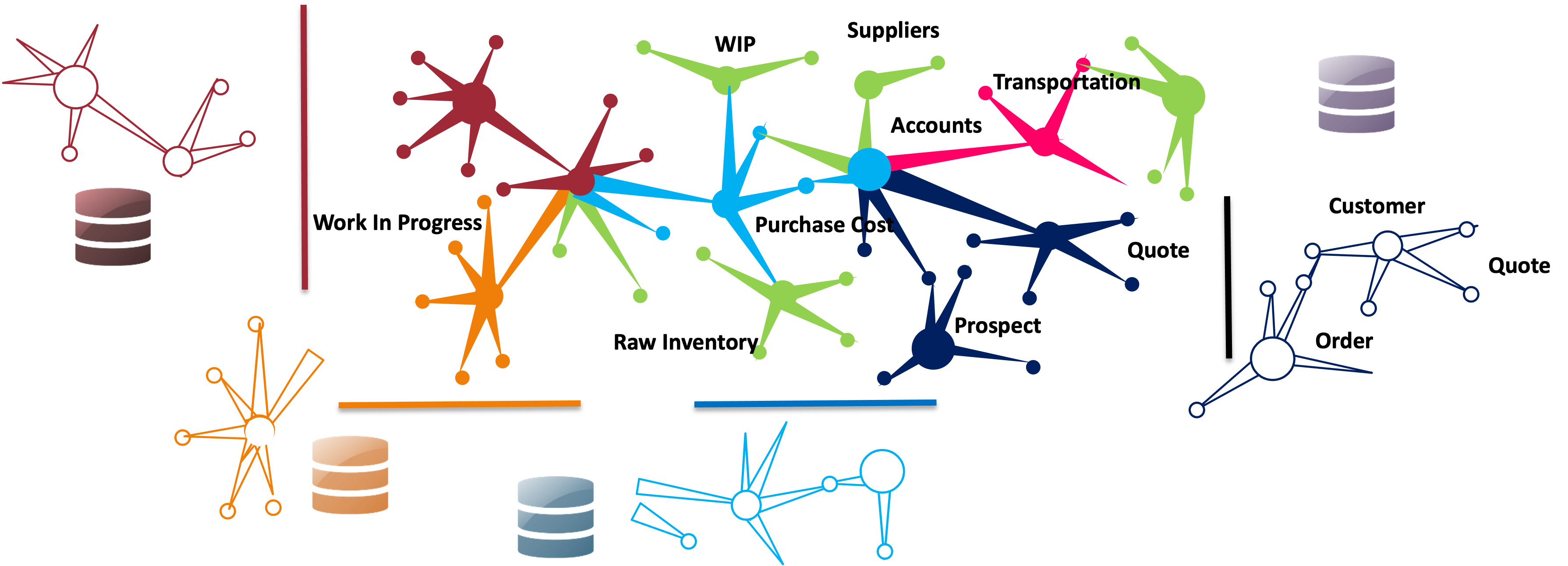
Data Fabric simply explained
Published:
What? Enterprise wide consisted data management design. Why? Reduce the time to deliver data integration and interoperability How? Through metadata.
Data Analytics Storage in 2024
Storage is foundational. The choices are simplified by the maturing technolgies. Providing a technical overview

Unified Enterprise Data Model
One Model to rule them all
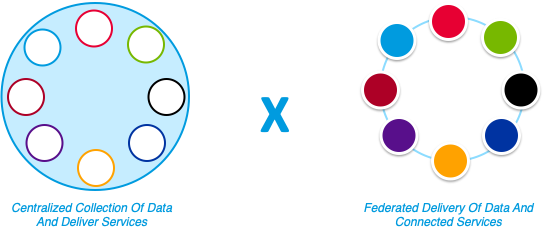
Centralized Vs Federated
Published:
Coming Soon
Example of a data architecture policy
A more effective format that is both simple and truly serves the intent of a policy

publications
Collect - Extraction: Batch Transfer
Published in Processing, 2024
Batch Transfer: One of the most common scenarios of extraction. For now atleast
Collect - Extraction: Transfer Compressed Data
Published in Processing, 2024
Move Compresssed data
Collect - Extract and Load Patterns
Published in Processing, 2024
Transfer data from source to taget
Collect: Pre-ingest vs Post-ingest Processing
Published in Processing, 2024
I do not tend to draw hard lines between applying processing logic directly on the source system before extracting the data or performing transformations post-ingestion in an analytics platform. Both approaches are valid, depending on factors such as data volume, complexity, real-time requirements, and system architecture. However, most modern data scale needs require processing to be done post-ingestion.
Collect: Data Profiling
Published in Processing, 2024
Data profiling is essential for understanding the quality, structure, and consistency of data
Curate: Data Cleansing
Published in Processing, 2024
Deliver quality data
Data Products: Adopting Microservice Architecture Principles
Published in Product, 2024
By applying microservice principles, data products can be designed to be modular, scalable, and maintainable, providing greater flexibility and agility in data-driven environments
Data Platform - Enteprise Semantic Layer Requirements
Published in Data Platform, 2024
Deliver Data as an Organized, Unified and Consistent Product
Data Store: Raw Layer
Published in Processing, 2024
Keep the Raw Layer “Raw”
Collect: Data Capture
Published in Processing, 2024
Capture data from source system for processing in an Analytics System
Federated Data Management through Domain-Oriented Decentralized Data Ownership
Published in , 1900
Leverage Business Capability Maps for Data Domains
MDM Patterns. All are relevant and can coexist
Published in Master Data, 2024
Leverage Business Capability Maps for Data Domains
Measure Data Architecture
Published in Governance, 2024
Consistency on what we measure and how we measure data domains. An method with an example scenario
talks
Data Engineering Project Initiation Checklist
Published:
Some upfront work is required to ensure the success of data engineering projects. I have used this checklist to provide a framework for collaborating with multiple stakeholders to define clear requirements and designs.
Snowflake Implementation Notes
Published:
Virtual Warehouses
Cloud Storage: Best practices
Published:
- Buckets names: I am split on wheter to have have smart names which clear inform about the intent of the bucket and its files and the security concerns that may arise by doing so. If there is a need to hide the intent of buckets from possible attackers, we would need manage and enforce catalogs. However, I have seen the worst of both worlds in which the naming is gives enough and these buckets not being cataloged. I would recommend a naming coventions or rules to catalog bucket names and have audits to ensure compliance.
Parquet: Best practices demonstration
Published:
A often overlooked feature of Parquet is its support for Interoperability which is key to enterprise data plaforms which serves different tools and systems, facilitating data exchange and integration. This is my take on Parquet best practices and I have used python-pyarrow to demonstrate them.
Table Formats Comparison Demo
Published:

Avro vs Parquet vs CSV Demo
Published:

Column Transformations for Staging
Published:

ConversationAI: Importing Documents
Published:

teaching
Iceberg Setup with Spark ETL and Nessie Catalog - Part 2
Lakehouse, Iceberg, Spark, 2024
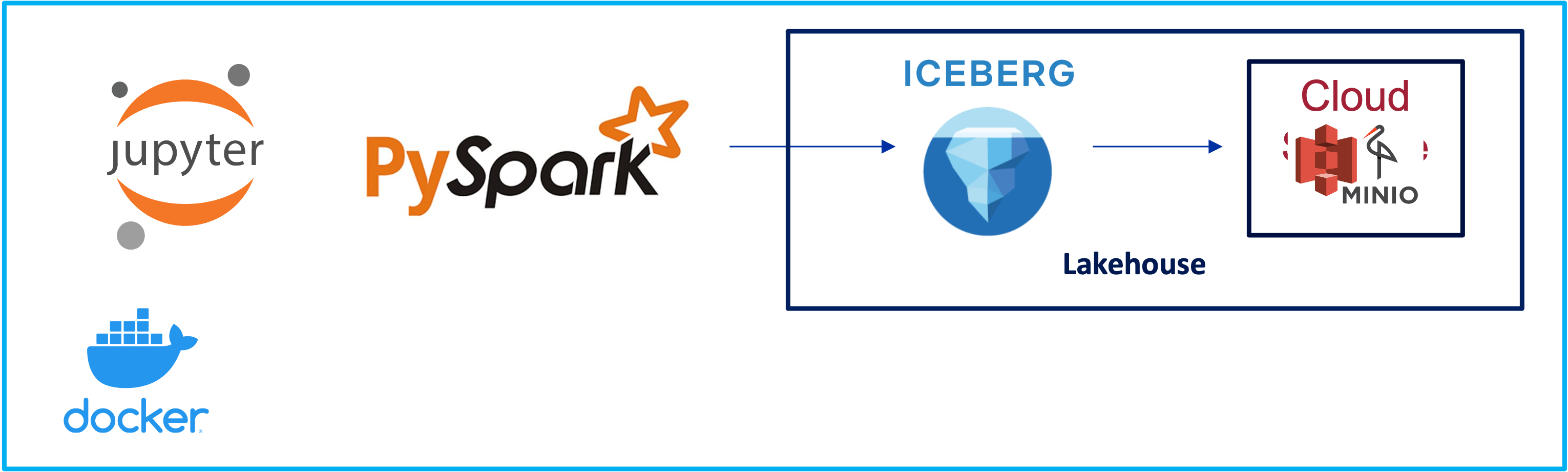
Iceberg Setup with Spark ETL and Nessie Catalog - Part 1
Lakehouse, Iceberg, Spark, 2024
MinIO Object Storage for Linux Locally (anywhere)
Lakehouse, Minio, 2024
When I play with new technologies, I like to plat it on my machine locally. Minio is a perfect simulation of cloud storage locally. You can deploy it locally and interact it like a S3 object storage.
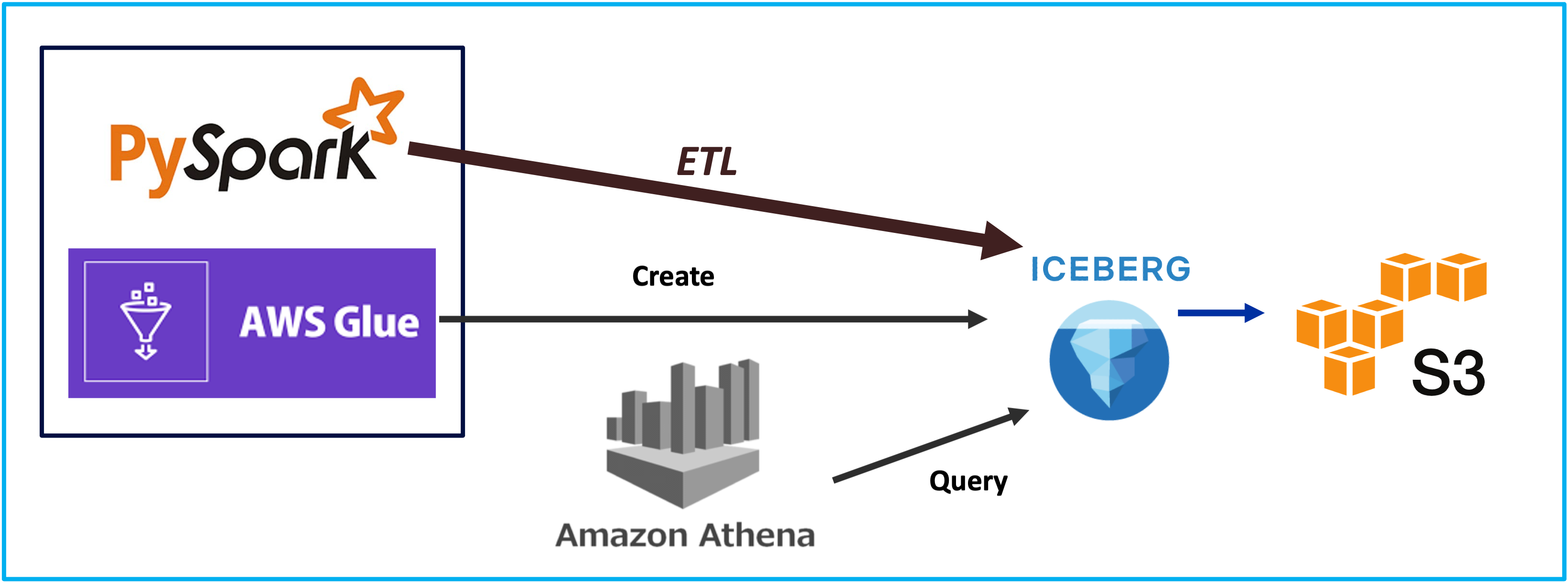
Iceberg on AWS: Part 2 - Glue 4 Loves Iceberg
Lakehouse, Glue, 2024
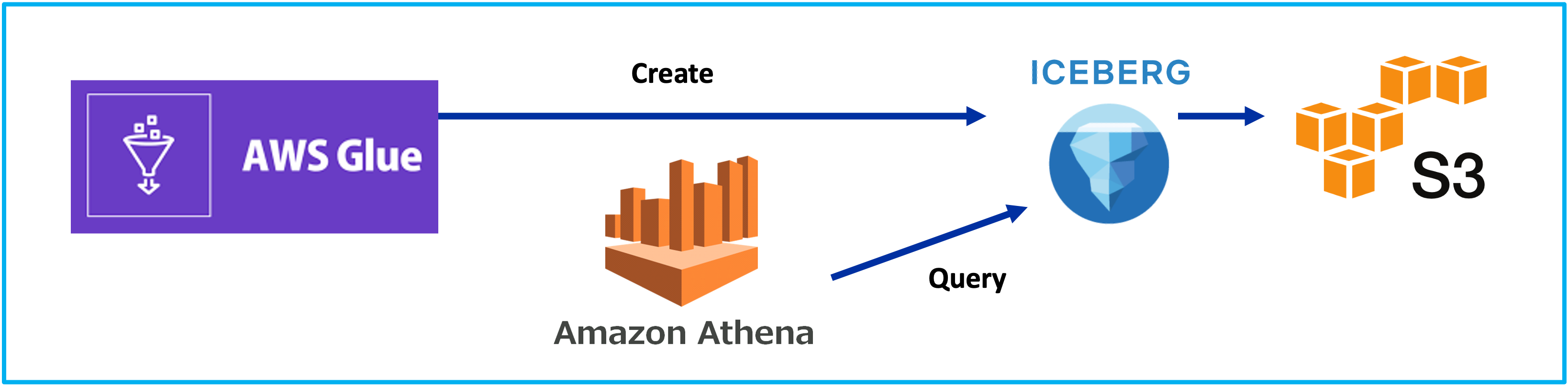
Iceberg on AWS: Part 1 - Hello World
Lakehouse, Iceberg, 2024
Local Development: AWS Lambda deployed in Docker with DynamoDB in NoSQLWorkbench
Application Service, AWS, 2024
Install DynamoDB locally
The installables can be found at the aws wbesite:https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/DynamoDBLocal.DownloadingAndRunning.html
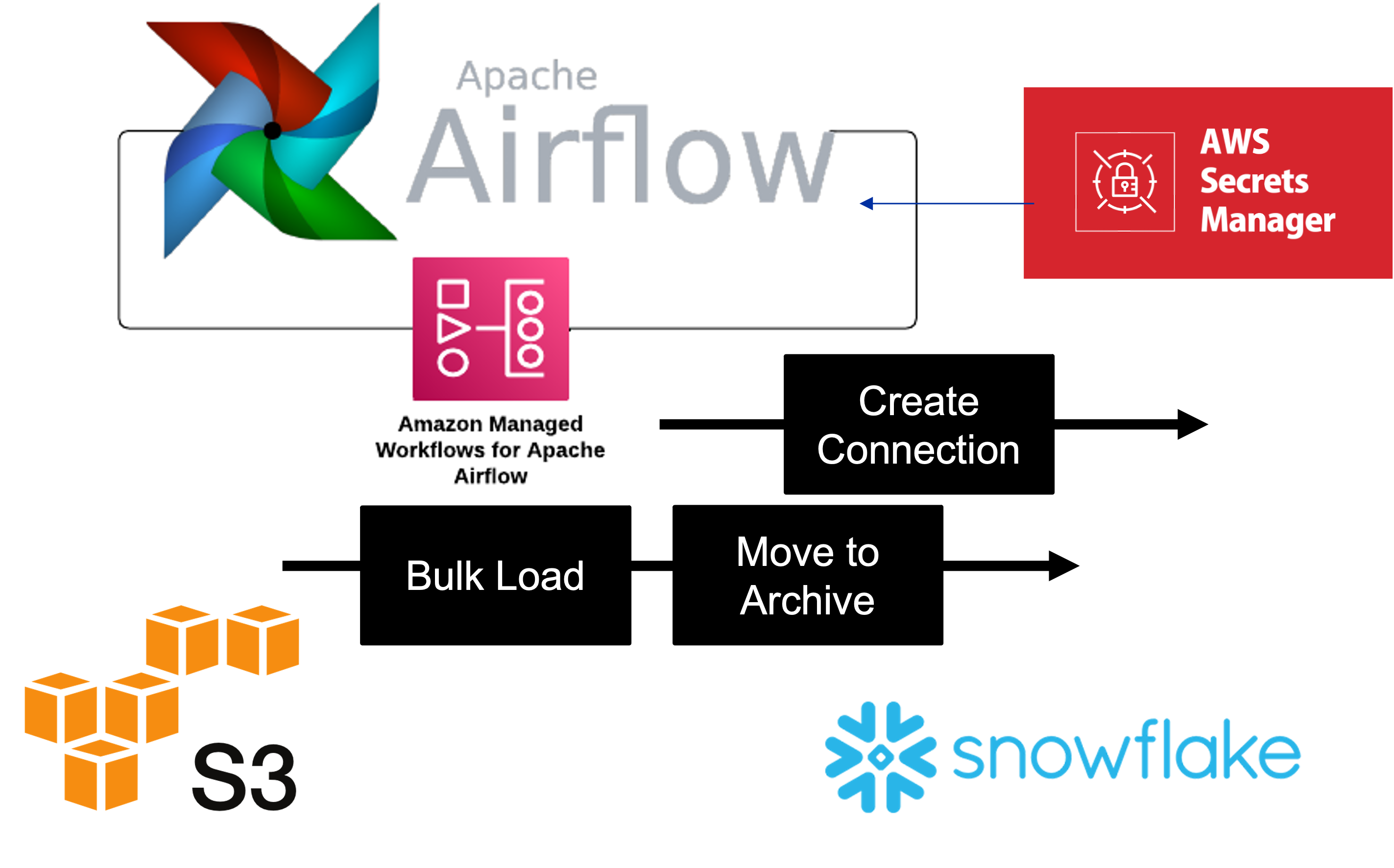
Apache Airflow: AWS Managed (MWAA) - Snowflake
Lakehouse, Airflow, 2024
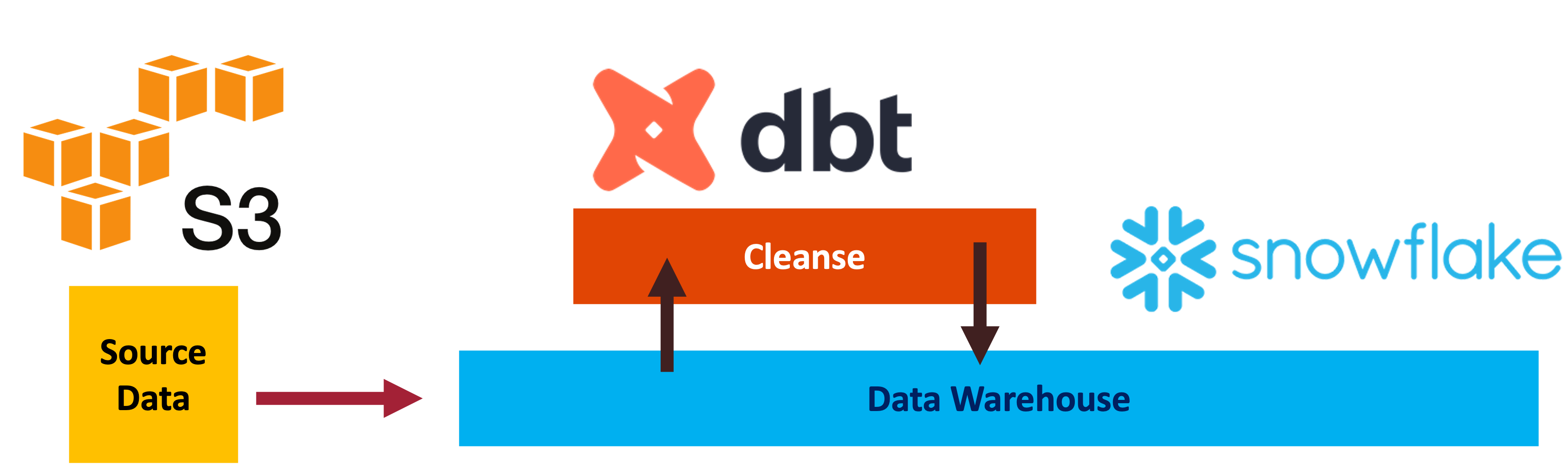
Data Processing with DBT and Snowflake
Data Warehouse, Snowflake, 2024
ETL Data Test and Validate
Data Warehouse, Snowflake, 2024
Setup
Installed DBT Core locally. The install configuration can be described by the command: dbt debug 
Installed DBT Utils 

DataFlow: Source Storage, Transform and Sink Biquery
Data Processing, GCP, 2024

Manage Data Quality With Great Expectations
Data Quality, Snowflake, 2024
Apache Beam Model. Clean and Simple
Data Processing, Beam, 2024

Apache Beam Using Pardo in DataFlow
Data Processing, Beam, 2024

Hive on EMR Serverless
DataLake, Glue, 2024

Infrastructure as Code - Terraform for Azure
Infrastructure, Azure, 2024

Collect: Airbyte Extract And Load to both S3 and Snowflake
Lakehouse, Airflow, 2024

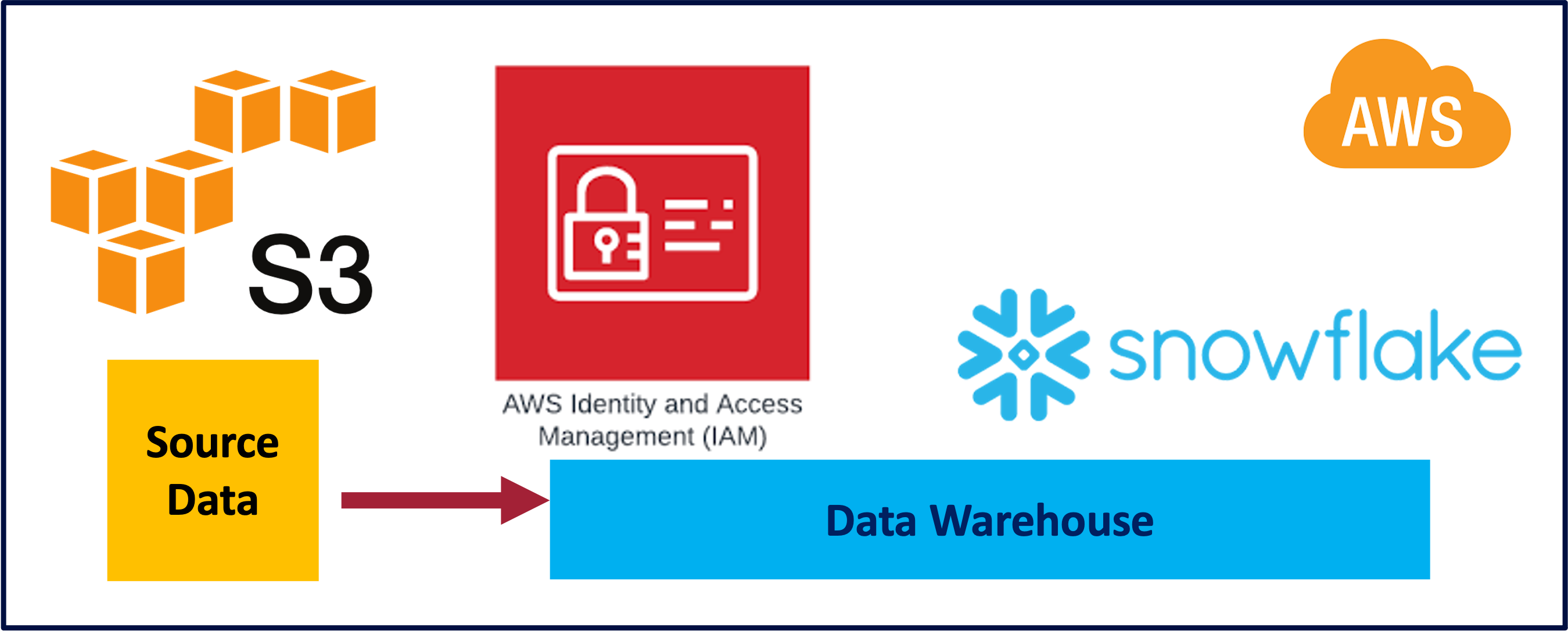
Snowflake: AWS S3 Loading
Datawarehouse, S3, 2024
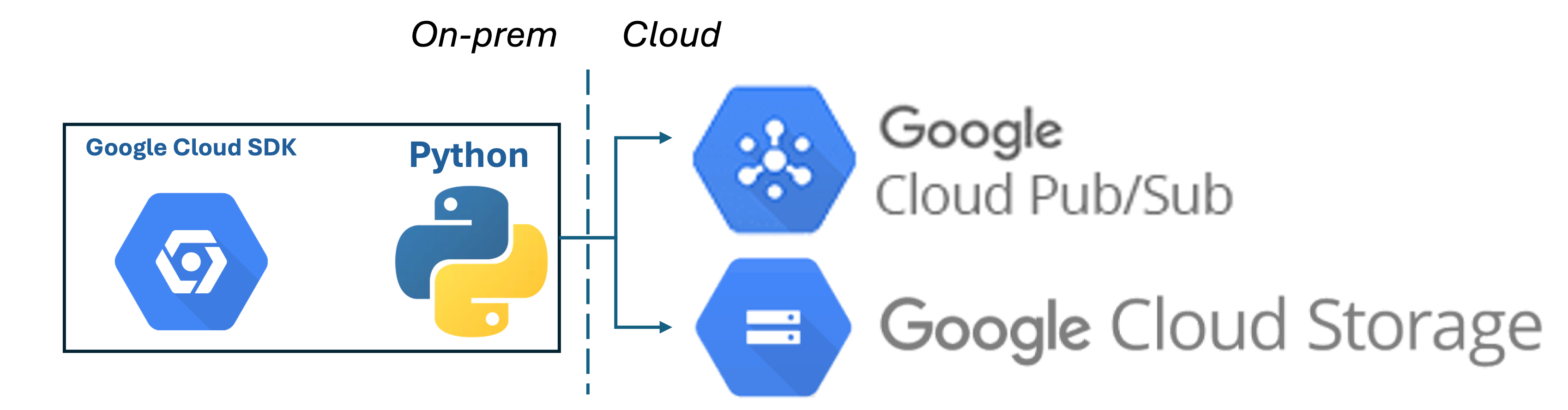
On-Prem gcloud SDK - Cloud Storage & Pub/Sub
gcloudSDK, GCP, 2024
Building Reliability in On-prem Data Upload Jobs Through Log Monitoring
Monitoring, GCP, 2024

GCP DialogFlowCX: Setup, Flow, Intent, Entities and Parameters
AI/ML, DialogflowCX, 2024

GCP DialogFlowCX Data store LLM generated agent responses based Knowledgebase in Storage.
AI/ML, DialogflowCX, 2024

AWS Lake Formation.
Data Lake, LakeFormation, 2025
AWS Lake Formation = Scaled Data Lake + Scaled Security Provisioning 
Hello PyTorch
Published:
The objective is to use the very basic example of linear regression and use PyTorch to build a model to demonstrate Pytorch workflow and its fundementals.
SpaceTitanic Pipeline - Model Impute - 81 score
Published:
The objective in this Notebook is to use a Pipeline to streamline development of code. I will not be focusing on data analysis and charts.
Machine Learning for daily tasks
Published:
I was tasked with planning demand for tickets for a complex Application Maintenance System that supports multiple companies. There was some historical data available, and it was invaluable. Using machine learning with sklearn, we were able to predict ticket volumes on a monthly basis with a very high degree of accuracy. Going through the usecase
Blog Post number 3
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
What is it that we want from our data architecture
This is the dream: We strive for a unified and usable data and analytic platform
What is unified data
A single, coherent, and consistent view of the data across the organization
Integrated Data
Combining data from different sources and providing a unified view
What is usable data
We need data to have an acceptable quality, readily available and easily accessible.
Data Governance
We want the data to be usable. How do we ensure it?
Data Management
Making Data Useful and Integrated:
Collect Architecture
Collect the data for analytics:
Curate Architecture
Curate the data for analytics:
Storage Architecture
Storage for Data Analytics: Coming Soon
Data Analytics Architectures
A Brief History
Data: Warehouse, Lake and Lakehouse
Yesterday, Today and Tomorrow of Data Processing
Data Fabric simply explained
Published:
What? Enterprise wide consisted data management design. Why? Reduce the time to deliver data integration and interoperability How? Through metadata.
Data Analytics Storage in 2024
Storage is foundational. The choices are simplified by the maturing technolgies. Providing a technical overview
Unified Enterprise Data Model
One Model to rule them all
Centralized Vs Federated
Published:
Coming Soon
Example of a data architecture policy
A more effective format that is both simple and truly serves the intent of a policy
Collect - Extraction: Batch Transfer
Published in Processing, 2024
Batch Transfer: One of the most common scenarios of extraction. For now atleast
Collect - Extraction: Transfer Compressed Data
Published in Processing, 2024
Move Compresssed data
Collect - Extract and Load Patterns
Published in Processing, 2024
Transfer data from source to taget
Collect: Pre-ingest vs Post-ingest Processing
Published in Processing, 2024
I do not tend to draw hard lines between applying processing logic directly on the source system before extracting the data or performing transformations post-ingestion in an analytics platform. Both approaches are valid, depending on factors such as data volume, complexity, real-time requirements, and system architecture. However, most modern data scale needs require processing to be done post-ingestion.
Collect: Data Profiling
Published in Processing, 2024
Data profiling is essential for understanding the quality, structure, and consistency of data
Curate: Data Cleansing
Published in Processing, 2024
Deliver quality data
Data Products: Adopting Microservice Architecture Principles
Published in Product, 2024
By applying microservice principles, data products can be designed to be modular, scalable, and maintainable, providing greater flexibility and agility in data-driven environments
Data Platform - Enteprise Semantic Layer Requirements
Published in Data Platform, 2024
Deliver Data as an Organized, Unified and Consistent Product
Data Store: Raw Layer
Published in Processing, 2024
Keep the Raw Layer “Raw”
Collect: Data Capture
Published in Processing, 2024
Capture data from source system for processing in an Analytics System
Federated Data Management through Domain-Oriented Decentralized Data Ownership
Published in , 1900
Leverage Business Capability Maps for Data Domains
MDM Patterns. All are relevant and can coexist
Published in Master Data, 2024
Leverage Business Capability Maps for Data Domains
Measure Data Architecture
Published in Governance, 2024
Consistency on what we measure and how we measure data domains. An method with an example scenario
Data Engineering Project Initiation Checklist
Published:
Some upfront work is required to ensure the success of data engineering projects. I have used this checklist to provide a framework for collaborating with multiple stakeholders to define clear requirements and designs.
Snowflake Implementation Notes
Published:
Virtual Warehouses
Cloud Storage: Best practices
Published:
- Buckets names: I am split on wheter to have have smart names which clear inform about the intent of the bucket and its files and the security concerns that may arise by doing so. If there is a need to hide the intent of buckets from possible attackers, we would need manage and enforce catalogs. However, I have seen the worst of both worlds in which the naming is gives enough and these buckets not being cataloged. I would recommend a naming coventions or rules to catalog bucket names and have audits to ensure compliance.
Parquet: Best practices demonstration
Published:
A often overlooked feature of Parquet is its support for Interoperability which is key to enterprise data plaforms which serves different tools and systems, facilitating data exchange and integration. This is my take on Parquet best practices and I have used python-pyarrow to demonstrate them.
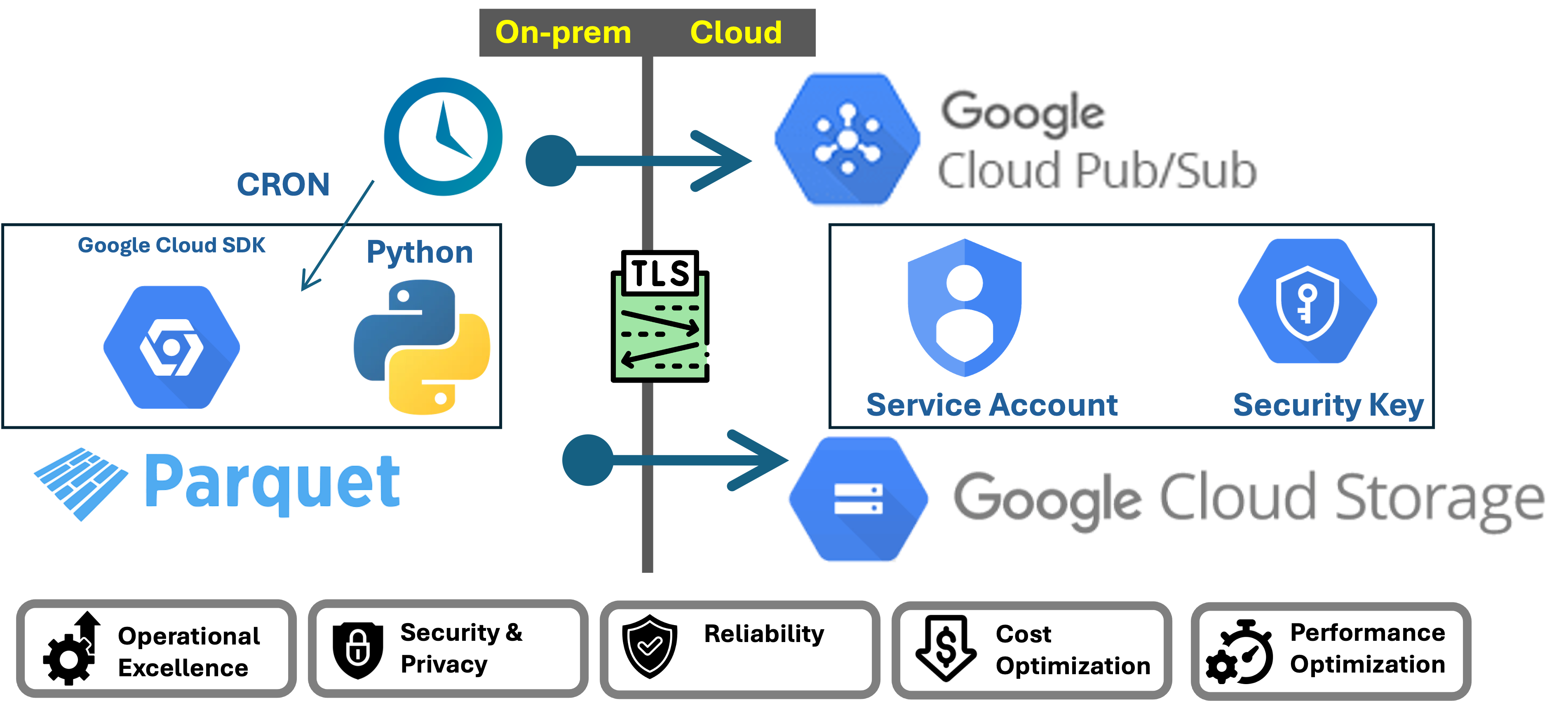
Table Formats Comparison Demo
Published:
Avro vs Parquet vs CSV Demo
Published:
Column Transformations for Staging
Published:
ConversationAI: Importing Documents
Published:
Iceberg Setup with Spark ETL and Nessie Catalog - Part 2
Lakehouse, Iceberg, Spark, 2024
Iceberg Setup with Spark ETL and Nessie Catalog - Part 1
Lakehouse, Iceberg, Spark, 2024
MinIO Object Storage for Linux Locally (anywhere)
Lakehouse, Minio, 2024
When I play with new technologies, I like to plat it on my machine locally. Minio is a perfect simulation of cloud storage locally. You can deploy it locally and interact it like a S3 object storage.
Iceberg on AWS: Part 2 - Glue 4 Loves Iceberg
Lakehouse, Glue, 2024
Iceberg on AWS: Part 1 - Hello World
Lakehouse, Iceberg, 2024
Local Development: AWS Lambda deployed in Docker with DynamoDB in NoSQLWorkbench
Application Service, AWS, 2024
Install DynamoDB locally
The installables can be found at the aws wbesite:https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/DynamoDBLocal.DownloadingAndRunning.html
Apache Airflow: AWS Managed (MWAA) - Snowflake
Lakehouse, Airflow, 2024
Data Processing with DBT and Snowflake
Data Warehouse, Snowflake, 2024
ETL Data Test and Validate
Data Warehouse, Snowflake, 2024
Setup
Installed DBT Core locally. The install configuration can be described by the command: dbt debug
Installed DBT Utils
DataFlow: Source Storage, Transform and Sink Biquery
Data Processing, GCP, 2024
Manage Data Quality With Great Expectations
Data Quality, Snowflake, 2024
Apache Beam Model. Clean and Simple
Data Processing, Beam, 2024
Apache Beam Using Pardo in DataFlow
Data Processing, Beam, 2024
Hive on EMR Serverless
DataLake, Glue, 2024
Infrastructure as Code - Terraform for Azure
Infrastructure, Azure, 2024
Collect: Airbyte Extract And Load to both S3 and Snowflake
Lakehouse, Airflow, 2024
Snowflake: AWS S3 Loading
Datawarehouse, S3, 2024
On-Prem gcloud SDK - Cloud Storage & Pub/Sub
gcloudSDK, GCP, 2024
Building Reliability in On-prem Data Upload Jobs Through Log Monitoring
Monitoring, GCP, 2024
GCP DialogFlowCX: Setup, Flow, Intent, Entities and Parameters
AI/ML, DialogflowCX, 2024
GCP DialogFlowCX Data store LLM generated agent responses based Knowledgebase in Storage.
AI/ML, DialogflowCX, 2024
AWS Lake Formation.
Data Lake, LakeFormation, 2025
AWS Lake Formation = Scaled Data Lake + Scaled Security Provisioning