
Apache Airflow: AWS Managed (MWAA) - Snowflake
Lakehouse, Airflow, 2024
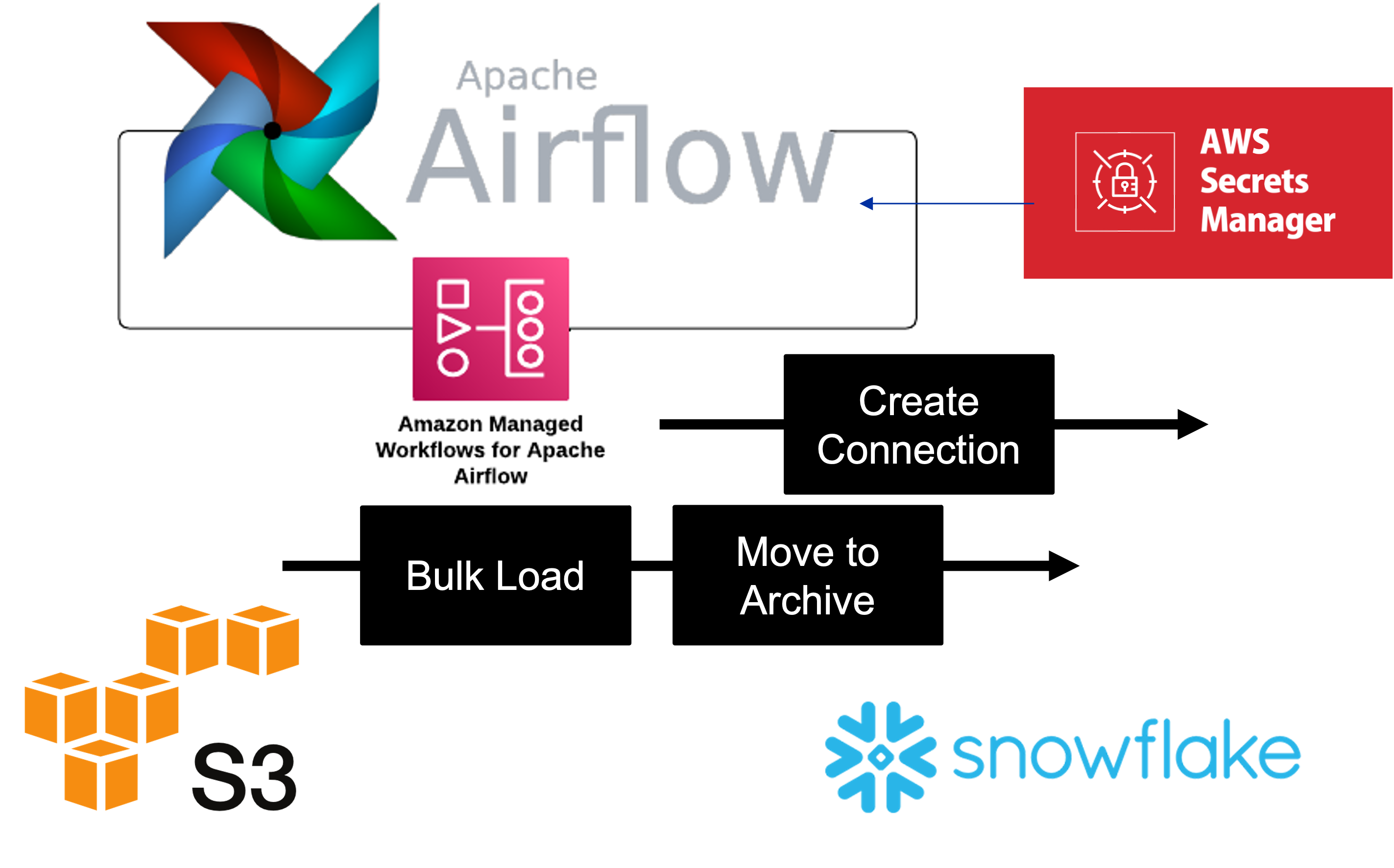
Loading data into Snowflake can be tricky. Loading needs many consideration for a successful data pipeline. Airflow can be a pain to manage. AWS has a decent job here. I am sure I would have struggled to get this without this being a managed service.
https://github.com/nuneskris/AWS_MWAA_Airflow_Play.git
As always use the official help to set things up https://aws.amazon.com/blogs/big-data/use-snowflake-with-amazon-mwaa-to-orchestrate-data-pipelines/
I am developing on top of the snowflake demo.
Objectives.
- To be able to use Airflow capabilities to orchestrate the loading of data into Snowflake.
- To use Airflow to archive files once they are loaded into Snowflake.
- Airflow to use Secrets Manager for Snowflake credentials
Setup
Snowflake
Snowflake setup from this demo.
AWS Managed Apache Airflow: MWAA
- I am using the latest version of Airflow. It is important to understand how versions can impact the installing of DAGs. Version: 2.9.2
- It was recommended to isolate a bucket for the Airflow enviroment: s3://airflow-dag-hello-kfnstudy
Within the airflow bucket we allocate a folder for DAG python files. s3://airflow-dag-hello-kfnstudy/dags
All dependencies we would need to define the in the requirements.txt
In the Airflow configuration options section, choose Add custom configuration value and configure two values: Set Configuration option to secrets.backend and Custom value to airflow.providers.amazon.aws.secrets.secrets_manager.SecretsManagerBackend. Set Configuration option to secrets.backend_kwargs and Custom value to {“connections_prefix” : “airflow/connections”, “variables_prefix” : “airflow/variables”}
- Follow the IAM configuration and access as per the document. We woult setup IAM for Airflow to have access to Secrets Manger and S3.
Requirements.txt
I made one mistake and it took nme a few hours to figure out the mistake I made. We would need to know the version of Airflow we are using and know the contrains ont he dependencies we would need to point to. I read the documentation and used the table to figure out the contraints txt I would need to point to: https://raw.githubusercontent.com/apache/airflow/constraints-2.9.2/constraints-3.11.txt
Below is the requirements.txt which worked for me.
--constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.9.2/constraints-3.11.txt"
snowflake-connector-python
snowflake-sqlalchemy
apache-airflow-providers-snowflake
apache-airflow-providers-amazon
Note:There are webservers logs which are very useful
Development
Secrets Manager
DAG:
To move setup and test a connection
This DAG which gets created when we upload the python file into the DAG folder.
This DAG connects to the secret manager, established and saves a connection to snowflake which can be reused by other dags and most finally tests the connection.
Airflow variables
We can set enviroment variables which can be access runtime by the DAGs
Connecting to snowflake via Secrets Manager
I have added comments.
# Name of connection ID that will be configured in MWAA
snowflake_conn_id = 'snowflake_conn_accountadmin'
def add_snowflake_connection_callable(**context):
### Set up Secrets Manager and retrieve variables
logger.info("Setting up Secrets Manager and retrieving variables.")
### hook to the secret manager
hook = AwsBaseHook(client_type='secretsmanager')
### client of the secret manager based on the region
client = hook.get_client_type(region_name=secret_key_region)
### secret based on the secret key
response = client.get_secret_value(SecretId=sm_secretId_name)
myConnSecretString = response["SecretString"]
secrets = json.loads(myConnSecretString)
# Only for inital debugging I kept the secrets on to ensure we read it correctly
# logger.info(f"Retrieved secrets: {secrets}")
Setting up a connection with snowflake
### Set up Snowflake connection connection: Connection = Connection( conn_id=snowflake_conn_id, conn_type=”snowflake”, host=secrets[‘host’], login=secrets[‘user’], password=secrets[‘password’], schema=secrets[‘schema’], extra=json.dumps({ “extra__snowflake__account”: secrets[‘account’], “extra__snowflake__database”: secrets[‘database’], “extra__snowflake__role”: secrets[‘role’], “extra__snowflake__warehouse”: secrets[‘warehouse’] }) )
Copy the URL from the above location to get the account and host: https://abc12345.snowflakecomputing.com
- abc12345: Account
- abc12345.snowflakecomputing.com: host
Creating a connection and adding it to the conneciton for reuse
session = settings.Session()
db_connection: Connection = session.query(Connection).filter(Connection.conn_id == snowflake_conn_id).first()
if db_connection is None:
logger.info(f"Adding connection: {snowflake_conn_id}")
session.add(connection)
session.commit()
else:
logger.info(f"Connection: {snowflake_conn_id} already exists.")
Note: Since this gets cached, we would need to ensure that we delete it so it can get recreated. There is a way which we can refresh this, but I did not have the time to figure it out.
The DAGS
with DAG(
dag_id='snowflake_kfnstudy_play_dag1',
default_args=default_args,
dagrun_timeout=timedelta(hours=2),
start_date=days_ago(1),
tags=['Snowflake', 'KFNSTUDY', 'DAG1'],
schedule_interval=None
) as dag:
add_connection = PythonOperator(
task_id="add_snowflake_connection",
python_callable=add_snowflake_connection_callable,
provide_context=True
)
delay_python_task = PythonOperator(
task_id="delay_python_task",
python_callable=lambda: time.sleep(10)
)
test_connection = SnowflakeOperator(
task_id='test_snowflake_connection',
sql=test_query
)
add_connection >> delay_python_task >> test_connection
The Run
I had some issues in the begining with the connection which I resolved (Account not correctly defined and the cache)
The logs also indicated there was no issues
2024-08-01, 22:49:17 UTC] {cursor.py:1149} INFO - Number of results in first chunk: 1
[2024-08-01, 22:49:17 UTC] {sql.py:487} INFO - Running statement: select distinct ORGANIZATION_NAME from SNOWFLAKE.ORGANIZATION_USAGE.RATE_SHEET_DAILY;, parameters: None
[2024-08-01, 22:49:23 UTC] {cursor.py:1149} INFO - Number of results in first chunk: 1
[2024-08-01, 22:49:23 UTC] {sql.py:496} INFO - Rows affected: 1
[2024-08-01, 22:49:23 UTC] {snowflake.py:410} INFO - Rows affected: 1
The fun part - The second DAG
In this DAG we will run the snowflake command to copy into the table multiple files and also move the files away into a seprate S3 folder via S3 command so that they will not be processed in the next run. Another common patter.
loading into snowflake
# snowflake_conn_id will configure Snowflake oprator to use the connection snowflake_conn_accountadmin
# which we had defined in the previous dag
DEFAULT_ARGS = {
'owner': 'airflow',
'snowflake_conn_id': 'snowflake_conn_accountadmin',
'depends_on_past': False,
'start_date': datetime(now.year, now.month, now.day, now.hour),
'retries': 3,
'retry_delay': timedelta(minutes=1),
}
The DAG is very simple. It will call the SnowflakeOperator which executes all the sql in the file.
# load datebase. the sql is saved in the file as indicated below
loaddatabase = SnowflakeOperator(
task_id='load_database',
sql='kfnstudy_snowflake_queries/load_database.sql'
)
The file has the below SQLs. Note we do not have to hard code the SQL. We can send paramters for this. Probably will do it in another demo.
USE DATABASE DB_PRESTAGE;
USE SCHEMA ERP;
COPY INTO SALES_ORDERS
FROM @KFN_S3_STAGE/sales_orders/
PATTERN='.*.csv'
ON_ERROR = 'skip_file';
Moving files
def move_files_s3(src_bucket, src_prefix, dest_bucket, dest_prefix, aws_conn_id='aws_default'):
s3 = S3Hook(aws_conn_id=aws_conn_id)
try:
# List files in source prefix
files = s3.list_keys(bucket_name=src_bucket, prefix=src_prefix)
if not files:
logger.info(f'No files found in {src_bucket}/{src_prefix}')
return
for file_key in files:
src_key = file_key
dest_key = file_key.replace(src_prefix, dest_prefix, 1)
logger.info(f'Moving file from {src_bucket}/{src_key} to {dest_bucket}/{dest_key}')
# Copy the file to the destination
s3.copy_object(
source_bucket_name=src_bucket,
source_bucket_key=src_key,
dest_bucket_name=dest_bucket,
dest_bucket_key=dest_key
)
# Delete the file from the source
s3.delete_objects(bucket=src_bucket, keys=src_key)
logger.info(f'Deleted file from {src_bucket}/{src_key}')
except Exception as e:
logger.error(f'Error while moving files: {str(e)}')
raise
The Run
There were 2 files which I had placed in the /erp/sales_orders/ folder.
Snowflake table is laoded with 2 files with 334 rows each.
The files are also moved into another location for arhival.
Closing Notes
I would recommend not to try AIRFLOW without dedicated engineers with this skill. But as a Managed Service doing all the heavy lifiting, I now consider this the superior orchestrator in the market.
All the best!