
Collect - Extract and Load Patterns
Published in Processing, 2024
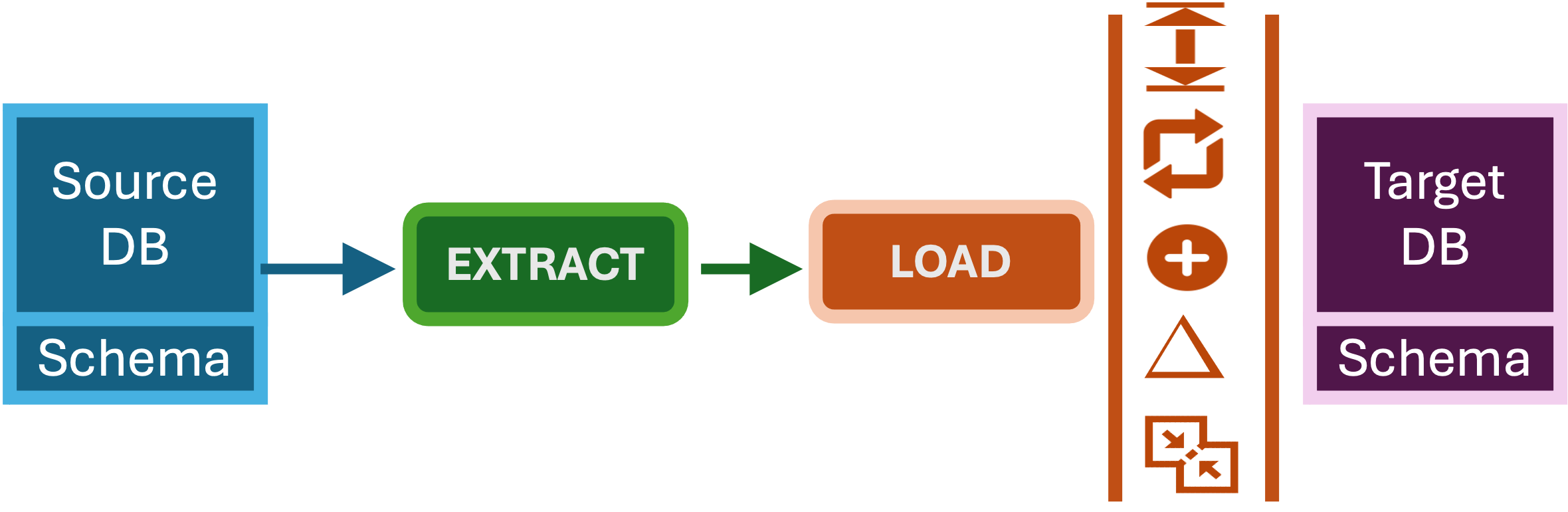
One of the more complicated task in data processing is extracting data which is captured at the source, possiblly move it accross the network and load the data into a totally different type of system for analytics processing. By being aware of the patterns for accomplishing this, helps us to make better decions in designing systems to accomplish this.
The Target system where the data is loaded can either be a schema-on-write where data needs to be loaded into a schema like relational-like databases or a schema-on-read database like cloud storage or HDFS.
Full Load
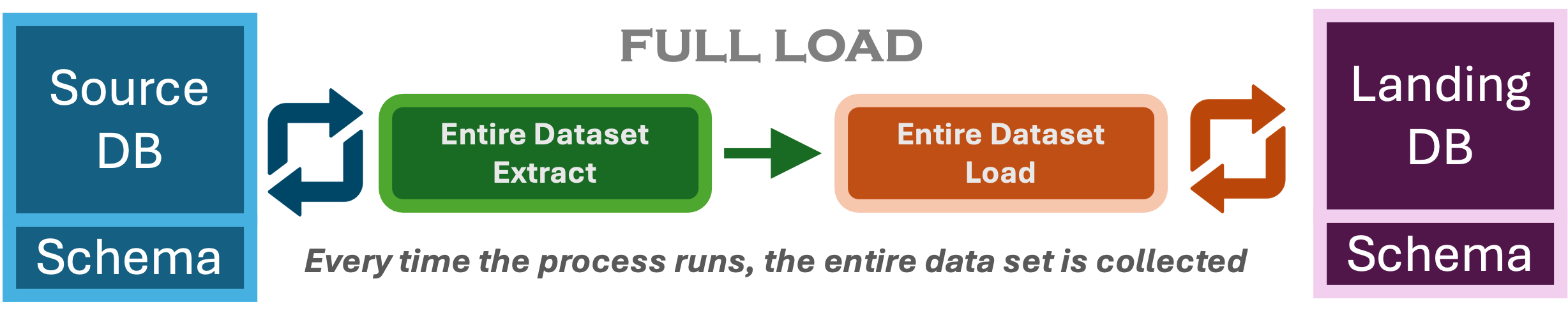
Every time the process runs, the entire data set is collected from the source into the target analytics system. This is the simplest pattern and I would recommend this for quick implementations where data is needed for analytics in short time and when the data is not too big. Note that ways we can evolve from this pattern to more sophisticated patterns. When do we use this pattern?
- Initial Data Load: This is usually pattern we would need even if we adopt an incremental load during initial loads.
- Data Reconciliation: There is a potential where the source and target of the extract and laod go out of sync and we would want to rebase them. The Full Load refresh can be use to rebase or reconcile our data.
- Snapshot: When we want to create snaphots in time of the entire dataset for historical reporting, trend analysis, or auditing.
- Operational Reporting: I have used fully loads for operational reporting when there is limited capabilities within the source application. Ideally the data would not require complex transformations and integration with data across the enterprise.
- Backup, Recovery, Compliance: An abvious reason this pattern is used is when snapshots of the data is completed ingested into Cloud storage for Backup, Recovery, Compliance & Audit.
- Downstream Delta Processing: This pattern is also used as part of a larger data processing pipeline, where transformation components deal with processing deltas.
Delta Load

Most often datasets get too big for full load, and collecting data changes will be able to scale. So, any new records in the source since the last sync are appended to the target database without modifying the data already existing. If a record is modified at the source, the new version is appended as a duplicate of the existing row. All incremental loads wihch are described going forward adopt this.
This is an incremental extract pattern where the data is loaded into a target location which is isolated for the load cycle, without consideration of the previous loaded data. However the multiple deltas can be logically combined with the existing data to create the entire dataset. The delta pattern is very commonly used to ingest data into cloud data storage, which is then further processed by downstream data processing applications for datawrehouse and datalakes.
- Landing Area: Most of the cloud ingestion patterns we use today uses this pattern where data is loaded into a cloud storage. We also call this the raw layer and I have page on best practices in managing this layer.
- Data Science Layer: Many of the data science layers happens in this layer where raw data is ingested into this layer.
Append Only Load
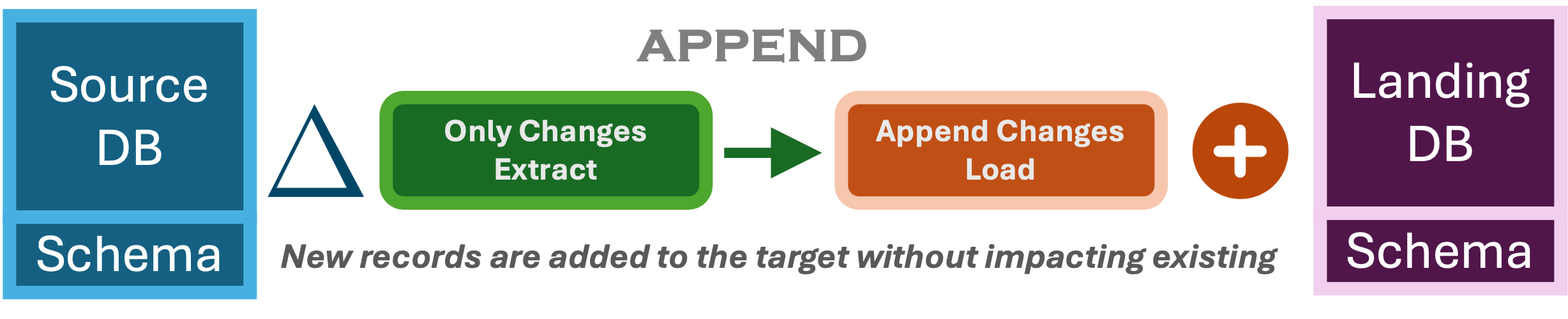
The dataset in the target is continously incremented with the new data appended to it. The load’s main functionality is to be able to append the data to the end (logically) of the previous sync.
- Immutable Target Database: This is another common dataset in the world of big data where the target databases are immutable and we can only add new data. Most of today’s landing zone uses this pattern where focus is on the extraction query offloading the data in a scallable cloud storage filesystems.
- Log File Processing: This was one patterns which I have used for processing application logs by Splunk. It is very important to design a schema where logs files from multuiple systems can be combined especially timestamp.
- Limited Load Processing Capabilities:
I have a demo on Append only extact and load of incremental data using Airbyte from a Postgres SQL Database into a Snowflake datawarehouse
Upsert

Upsert is a combination of “update” and “insert”. Simply explained, if a record exists, it is updated; if it does not exist, it is inserted. This is useful when dealing with datasets where records need to be both updated and newly inserted. Its is important to consider requirements in handling of primary keys or unique identifiers to match records to perform an update operation. I personally find the outcome of Append and duplicate the same as Upsert and use them interchanginly.
This provides a simple that logic needed to handle both new and existing records for maintaining a single source of truth with the most current data.
I have a demo on Append and deduplicate or Upsert incremental data using Airbyte from a Postgres SQL Database into a Snowflake datawarehouse.
SCD2
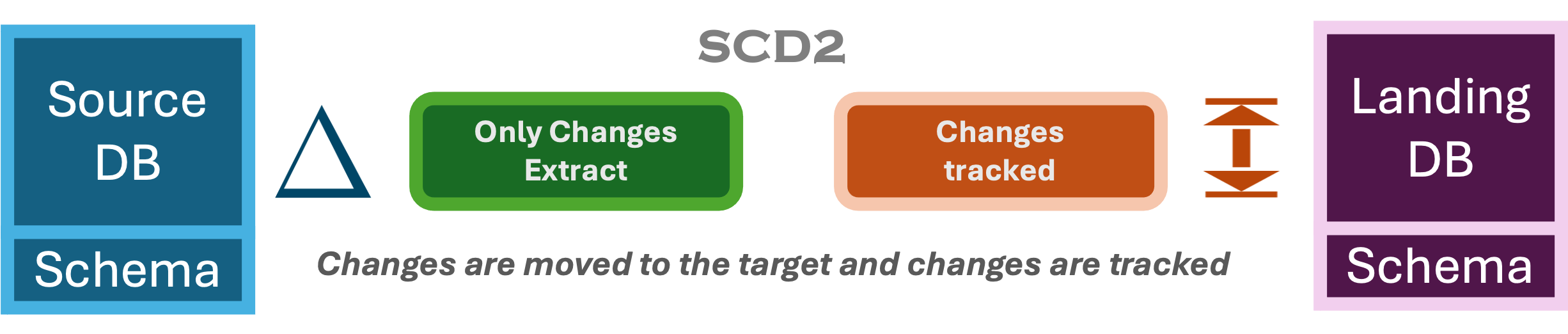
Dimension modeling irrespective of the type of analytics modeling (dimensional vs wide) for analytics requires to track inserts, updates, and deletes of entities to allow querying these changes. SCD2 is when we track the change as a seperate row which I explain in a demo using Glue, Pyspark on a Iceberg Datalake. Most data warehousing processing tools such as DBT have multiple built in capabilities to handle SCD2 seemlessly.
External Reference
- https://nuneskris.github.io/talks/IncrementalAppendLoad
- https://nuneskris.github.io/talks/Slowly-Changing-Dimensions
- https://nuneskris.github.io/talks/IncrementalLoadWithDemo
- https://nuneskris.github.io/talks/IncrementalAppendLoad
- https://nuneskris.github.io/talks/Extract-Batch-Transfer)