
Collect - Extraction: Transfer Compressed Data
Published in Processing, 2024
Compressing data during ETL ingestion into the cloud offers several benefits, primarily related to performance, cost, and efficiency. Cloud storage costs are typically based on the amount of data stored. Compressing data reduces its size, leading to lower storage costs.
Most importantly, compressed data is smaller, which means it can be transferred more quickly over the network. This is particularly important when moving large volumes of data to the cloud, as it speeds up the ingestion process and reduces the load on network resources, saving on bandwidth costs and time, which can be significant, especially when dealing with large volumes of data. An added bonus is cloud analytics tools naturally perform better with compressed data because they need to read less data from storage.
I have a demo on how we can naturally use compressed formats on this page.
I have another
# Write the table to a Parquet file with dictionary encoding for 'category' and default encoding for others
pyarpq.write_table(
pyar.Table.from_pandas(df_salesOrder, preserve_index=False),
'Data/SalesOrders.parquet',
use_dictionary=['SALESORG','LIFECYCLESTATUS','BILLINGSTATUS','DELIVERYSTATUS'], # Specify dictionary encoding for the 'category' column
compression='SNAPPY', # Use compression for better storage efficiency
data_page_version='2.0', # Use data page version 2.0 for better performance
write_statistics=True
)
Below is a case study which reflects highlights an uncommon mistake folks make.
Context
I have asked to analyze ETL issues which plagued a large manufacturing company. Data Stage was used for around 400 ETL Jobs to move and curate data from DB2 to AWS data warehousing needs. Most of their issues was supporting an SAP data workload which did some preprocessing on-premise and moved the data to S3 for further processing and analytics. Most of the issues were uncovered only when the data had reached S3 after a lead time of 9 hrs. There was a lot of processes in play to monitor the job which involved hand shakes by support engineers. Much of the energy was spent managing these processes to avoid these failures. Any issues or delays triggered SLA which were very tight and the loads were often a few days behind.
Task
I was to analyze the ETL jobs based on the ETL best practices. I walked through the flow with the logs and identified that the step where data is being loaded into S3 was the delay. There were around 150 files which were transferred to S3, larger files were broken to 5GB lists or 20 million rows. MARD had 56 million rows. These 5 GB files were transferred at 1.6 MB/s typical of enterprise upload speeds taking 50-70 mins for 5 GB. This totaled 8 hours of transfer time, which could be negated and reduce the time pressures significantly.
Action
I proposed a simple fix of compressing the files. The reason data was transferred as uncompressed was the original developers did not run a proper load test and AWS Data scientists wanted the data as flat files.
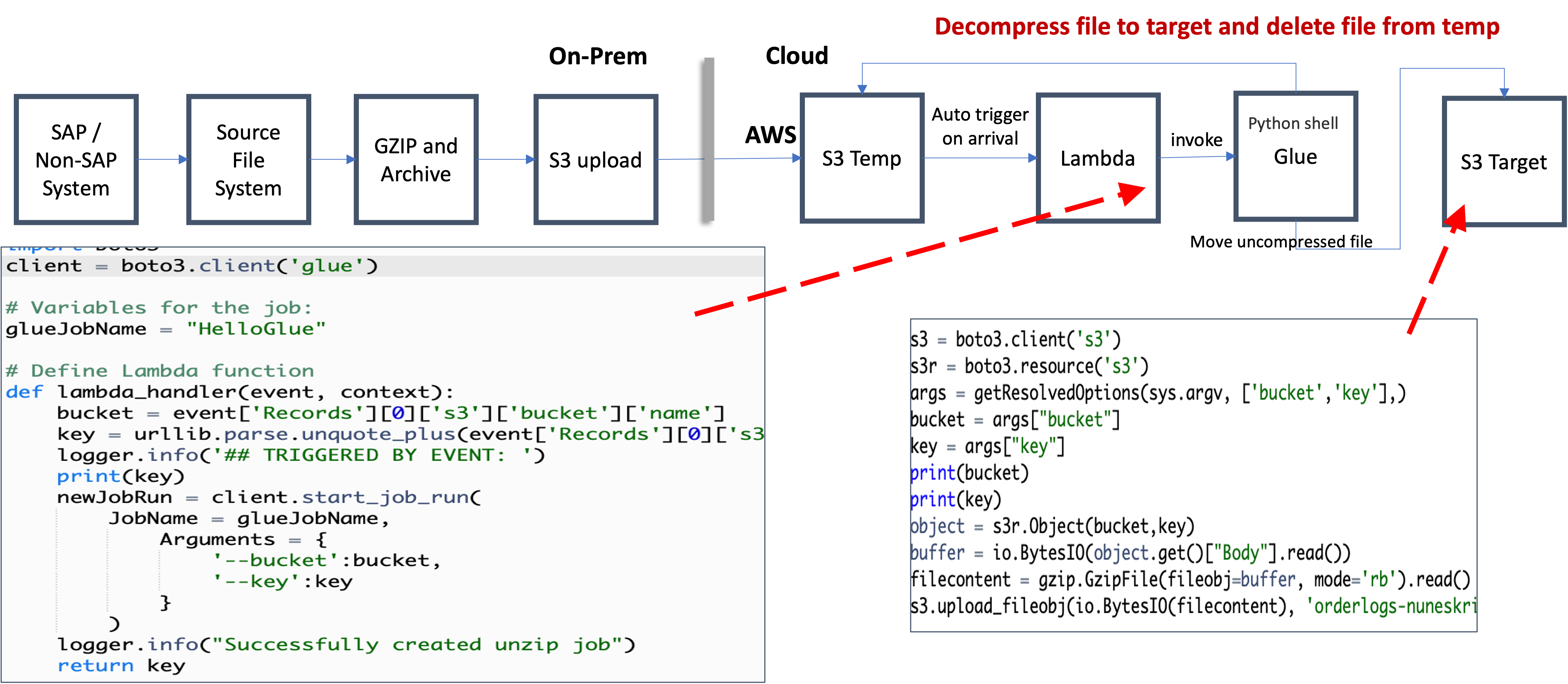
Result
Compressed large files and sent to S3. The current gzip operation compressed 5GB file to ~100 MB (~ compression ratio of 50) reducing it by 98%, bringing the 8hrs to 10mins. Use server-less solution: Lambda function are trigger on arrival of the large file which triggers Glue to un-compress the file back to S3. This would incur a cost or $25 for Lambda and Glue.
Pricing
Lambda would need memory of 128 MB allocation. Even with 30 million invocation each month would cost $11 per month. An AWS Glue job of type Python shell can be allocated either 1 DPU or 0.0625 DPU. By default, AWS Glue allocates 0.0625 DPU to each Python shell job. You are billed $0.44 per DPU-Hour in increments of 1 second, rounded up to the nearest second, with a 1-minute minimum duration for each job of type Python shell. Max cost of $15 per month