
Extract: Batch Transfer From Onprem To Cloud (GCP)
Date:
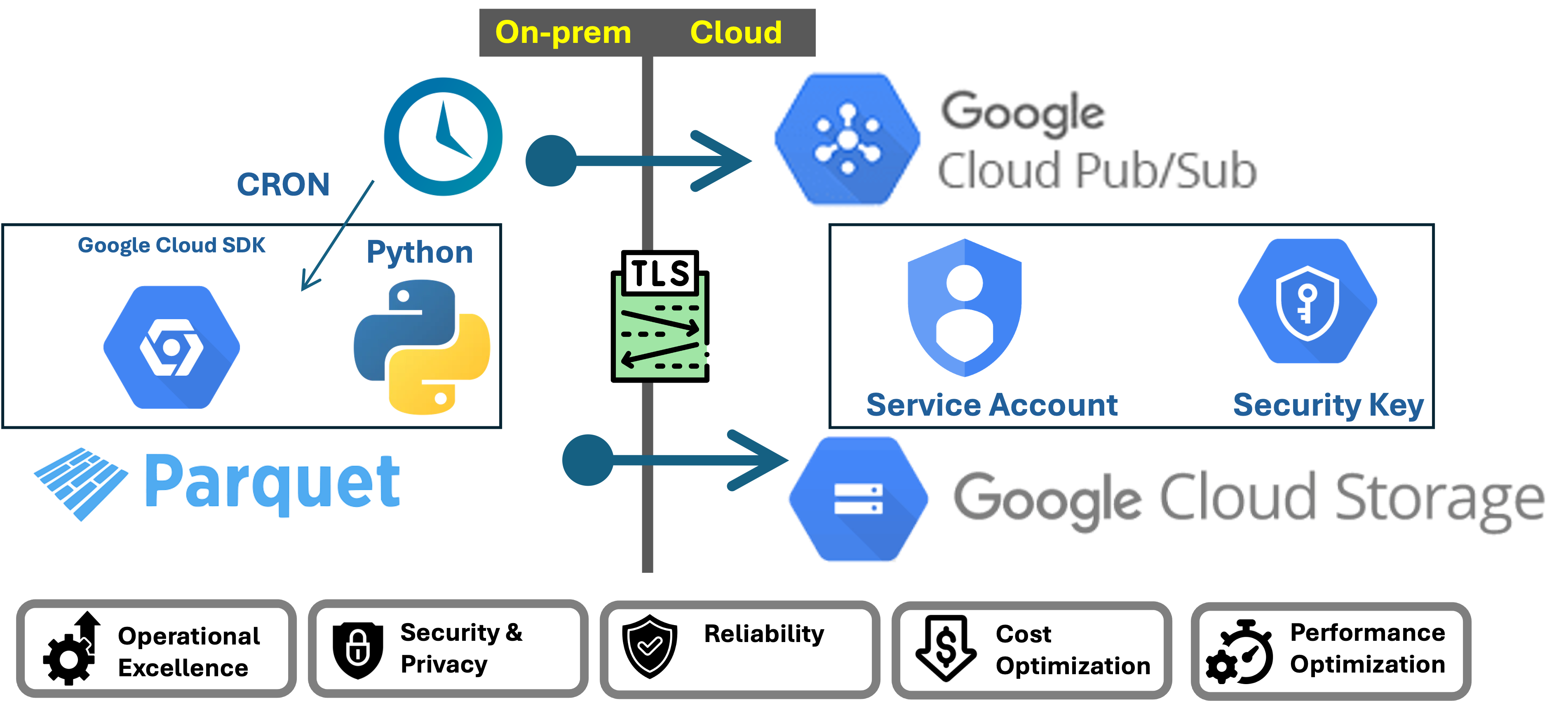
Typicall workloads begin with flatfiles which are extracted from the source system which are either in CSV or Parquet. We will require to transfer these files into the cloud. The solution is very straight forward
- Python gcloud sdk to upload the files
- Cron job to schedule the job
However, many would say that this solution is not enterprise grade. I will use the architecture pillars and enhance the subsytems to deliver a system which is secure, reliable, performant and cost optimized while conforming to operational excelence standards.
1. Automation and Scheduling
We need a mechanism which can be easily be scheduled. We are basically trying to not rely on complex orchestration tools which either need to be deployed on-prem or struggle with a solution which needs to get across the cloud network into the on-prem which can be a nightmare with threat controls.
Cron is a tried and tested option to schedule jobs. With proper documentation and maintenance, it can be a very reliable solution.
First we would need to find the correct Python path
which python3
Edit the crontab
We would need to edit and add the schedule to the crontab
crontab -e
Update the cron job entry with the correct Python path
*/5 * * * * /<path to python>/python3 /<path to code>/upload_to_gcs_scheduler.py >> /<path to log>/upload_to_gcs_scheduler.log 2>&1
We can verify the cron job
crontab -l
2. Logging
An often forgotten aspect of substems which support the pipeline is the logging. Since we have complete control on the susbystem, we can customize logging based on our needs. Python supports simple solution for loggig.
import logging
.
.
# Setup logging
logging.basicConfig(filename='/Users/xxxxx/DataEngineering/ETL/Collect/Ingest/GCPUtilCopy/logfile.log',
level=logging.INFO,
format='%(asctime)s %(levelname)s %(message)s')
.
.
# logging
logging.info(f"INFO: {datetime.now().strftime('%Y%m%d%H%M%S')}: File {local_file_path} uploaded to {destination_blob_name}")
If there is a need to pesist the logs in a more robus soltuion, we could publish these messages to the cloud via pub/sub.
3. Pub/Sub Notification
We can publish logs to Cloud Pub/Sub and leverage cloud storage persist, logging and monitoring capabilities to build the needed reliability. Below are the typical logs which we would need to publish.
Job Started
Job Info Logs
Job Complete
Job Error
I have a demo on how to publish notificaitons to Pub/Sub from an on-prem client.
I have another demo: Building Reliability in On-prem Data Upload Jobs Through Log Monitoring on how to monitor message using Cloud Function for Cloud Logging and use Cloud Monitoring for Alerting, Notification and Incident Management
4. Retry Logic
Implementing retry logic within the Python script to handle transient errors is straight forward. This can be done using libraries like tenacity for retries. **Retry logic for sending Notificaiton on the the job**
# retry after 5 mins, 5 times.
@tenacity.retry(wait=tenacity.wait_fixed(60), stop=tenacity.stop_after_attempt(5))
def publish_message(project_id, topic_id, message):
Testing the retry logic by turning of the internet. There is a pause for 5 mins and retries. It was able to successfully send the message on the retry after I turned on the internet.
**Retry logic for Transfer of Data**
@tenacity.retry(wait=tenacity.wait_fixed(5), stop=tenacity.stop_after_attempt(5))
def upload_to_gcs(local_file_path, bucket_name, destination_blob_name, json_credentials_path):