
On-Prem gcloud SDK - Cloud Storage & Pub/Sub
gcloudSDK, GCP, 2024
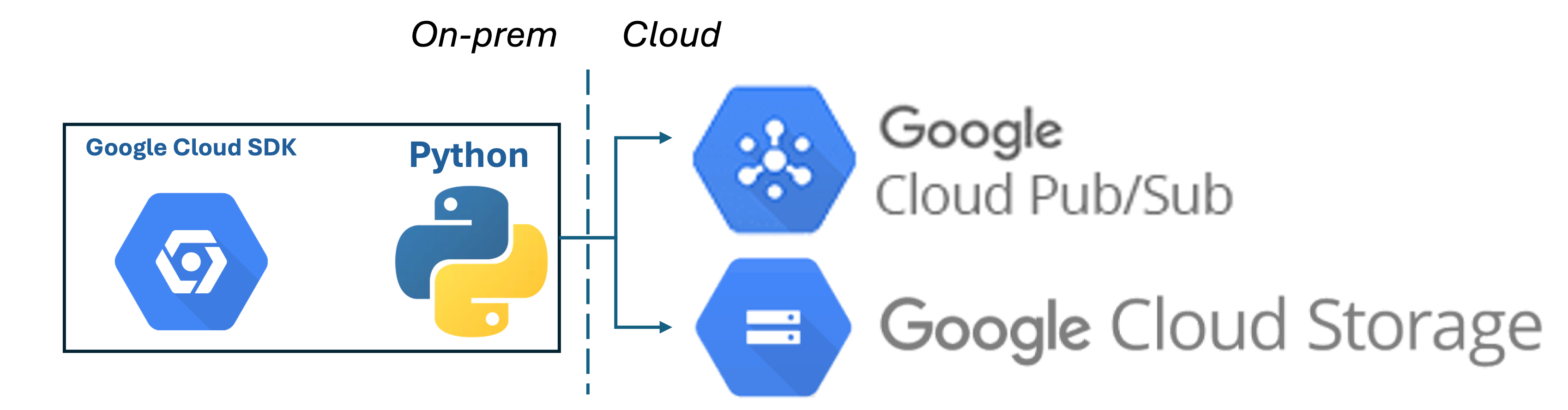
The objective of this demo is to be able to use gcloud and simulate on-prem data engineering capabilities required in multiple scenarios. We will use gcloud python SDK to (1) upload data files to GCP Cloud Storage and (2) Publish status notificaiton to GCP Pub/Sub on whether the ingest happened.
Cloud Security - IAM Service Account
We woud need to create service account which will used by the client to authenticate into GCP using secret keys.
For the Service Account to be able to access Cloud Storage we would need priviledges to the destination bucket. Below are the permissions required by the service account.
- Storage Object Creator
- Storage Object Viewer
For the Service Account to be able to access Pub/Sub we would need to priviledges as below
- Pub/Sub Publisher
This key file which will include IAM Service account detailsa and security key details will need to be download and used by the client.
Create a Bucket which will be used for laoding data
I am creating a base for interest of time. I would usually have the bucket name is randomized for security reasons. Also ensure that the name right security is applied on the bucket based on the recommendation of the Raw-Layer.
Create a Topic and Subscription
gcloud Python SDK
Cloud Storage. This will upload a file to the specified bucket.
json_credentials_path = '/Users/xxxxxxxxxxxxx.json
def upload_to_gcs(local_file_path, bucket_name, destination_blob_name, json_credentials_path):
client = storage.Client.from_service_account_json(json_credentials_path)
bucket = client.get_bucket(bucket_name)
blob = bucket.blob(destination_blob_name)
blob.upload_from_filename(local_file_path)
bucket_name = 'ingest-xxxxxx'
project_id = 'durabxxxxxx-g7'
topic_id = 'topic-xxxxxxxn'
def publish_message(project_id, topic_id, message):
# Initialize the Publisher client
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_id)
# Encode the message to bytes
message_bytes = message.encode('utf-8')
# Publish the message
future = publisher.publish(topic_path, data=message_bytes)
Run
Data is loaded into the bucket. We can see the parquet files uploaded based on the filenames passed to the funciton defined above.
The subcription also has recevied the notifications as we can see below.