
Collect: Data Capture
Published in Processing, 2024
For the initial load we would extract all data. This will be a one-time process where all historical data is pulled into the target system. If the initial load is too large, break it into smaller batches to avoid overloading the source system.
Implementation Tip: Very often the inital load is not a simple query on the enitre table because we will hit into size contraints either because of data query tools hit a limit, transfer contraints or downstream systems are not able to read large files. We would need to break these large captures into smaller batches. These batches need to be tested early. Additionally, we need the capability to rebase the entire dataset from the source when issues with the data arise.
However in this page we will discuss the ways to capture source data changes and depending on the scenario we would need to choose the best option.
Leveraging Timestamp Audit Columns on the database
Modern source applications include timestamp audit columns that store the date and time for every row that is either created or updated. These columns are internally managed. This is the first capability of the source system we need to analyze when designing the component to capture data.
Analyze Timestamp Audit Columns
Analyze each table to ensure the timestamp audit column (created_at, updated_at, deleted_at) are accurate and reliable. There can be issues if these columns are generated by custom implementations. Verify that all timezone consistency on all the timestamp columns to avoid inconsistencies during extraction.
Handling Deletes
- If the source system uses soft deletes (marking a row as deleted without physically removing it), ensure the deleted_at column is used to capture these records. This is the least complex in handling deletes.
- If the source system performs hard deletes (physically removing records), we would not have an audit column to indicate deletes, we would need to handle it separately in one of the scenarios below.
Watermarking
We need implement a watermark where the last successfully extracted timestamp is recorded. This will be used as the starting point for the next extraction. There needs to be a way this can be provided as an input for the queries to define the batch window.
Cut-off Times
We need to ensure that the extraction process considers transaction boundaries. In most cases, we find that these tables are updated by a single transaction, which is what is desired. If there is a transaction that updates more than one table, all the tables would have the same timestamp. However, while this level of detail might seem excessive, it is important to define the cut-off time for the entire batch up to the last complete transaction to avoid partial data. These Batch Windows need to specify the start and end times for each incremental extraction. Folks only configure the start time. I have seen a situation where the source application teams did a select statement based on the current time stamp for indivual querires which created partial records. Simillarly I was asked to analyze anothe situation where duplicate records were created and it was because there was a race condition where records came through into tables which were queued for extraction while waiting for previous table to complete.
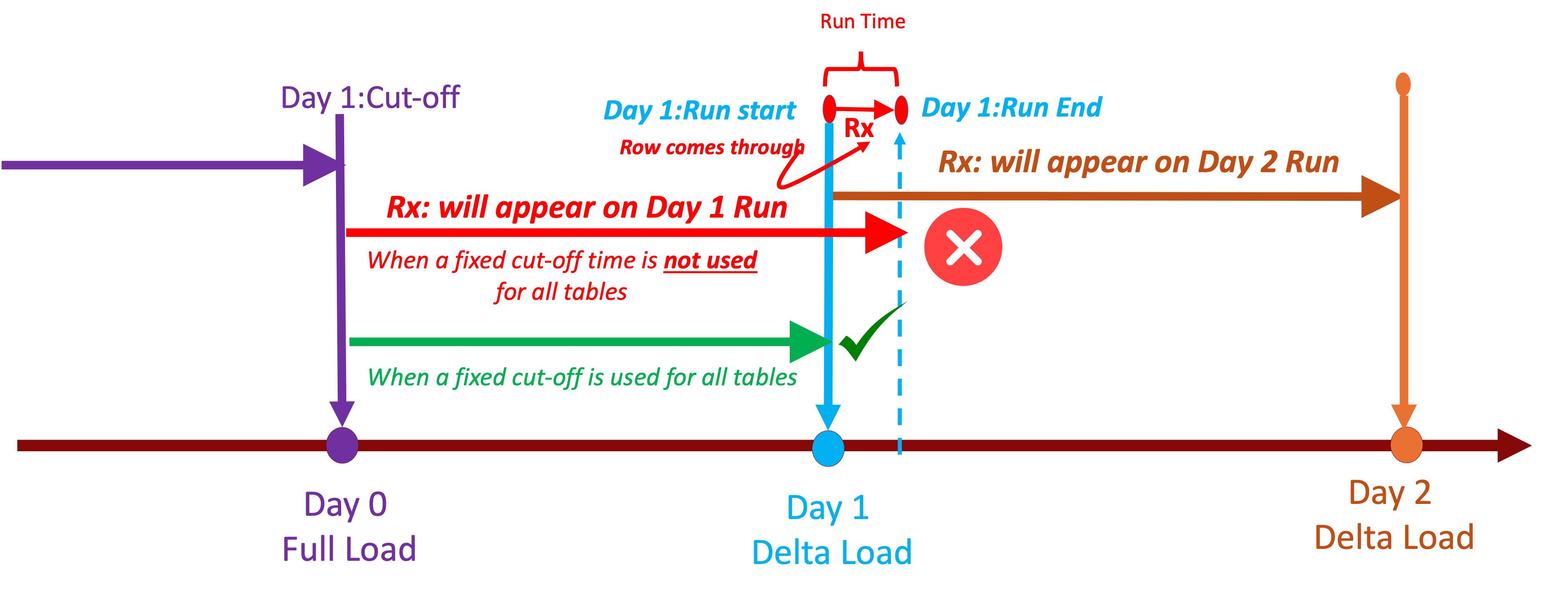
Perform a Date Range Check to verify that date columns fall within expected ranges. Implementation: Check for invalid date ranges.
SELECT id, date_column FROM source_table
WHERE date_column < 'LAST_CUT_OFF' OR date_column > 'CURRENT_CUT_OFF';
No timestamp column - We would need to compare the rows.
This is a resource intensive approach where we build a full difference compare query between the data which is in the application system and data which is in the analytics system. Use this option only when we do not have other otions.
Comparison Logic
- Ensure every table has a primary key or a unique identifier to accurately identify records. The logic is simple and similar to the below logic but very often missed with dire consequences.
-- Current state of the data
WITH current_data AS (
SELECT id, col1, col2 FROM source_table
),
-- Previous state of the data (last snapshot)
previous_data AS (
SELECT id, col1, col2 FROM staging_table
),
-- Identify new records
new_records AS (
SELECT c.id, c.col1, c.col2 FROM current_data c LEFT JOIN previous_data p ON c.id = p.id WHERE p.id IS NULL
),
-- Identify updated records
updated_records AS (
SELECT c.id, c.col1, c.col2 FROM current_data c JOIN previous_data p ON c.id = p.id WHERE c.col1 != p.col1 OR c.col2 != p.col2
),
-- Identify deleted records
deleted_records AS (
SELECT p.id, p.col1, p.col2 FROM previous_data p
LEFT JOIN current_data c ON p.id = c.id WHERE c.id IS NULL
)
-- Combine all changes
SELECT * FROM new_records UNION ALL SELECT * FROM updated_records UNION ALL SELECT * FROM deleted_records;
There was a case where we computed hash values for the significant columns we were interested in and used that to easily compare data between snapshots.
-- Generate hash values
SELECT id, MD5(CONCAT_WS('|', col1, col2)) AS source_hash FROM source_table;
SELECT id, MD5(CONCAT_WS('|', col1, col2)) AS target_hashFROM target_table;
-- Compare hash values
SELECT s.id
FROM (SELECT id, MD5(CONCAT_WS('|', col1, col2)) AS source_hash FROM source_table) s
JOIN (SELECT id, MD5(CONCAT_WS('|', col1, col2)) AS target_hash FROM target_table) t ON s.id = t.id
WHERE s.source_hash != t.target_hash;
Consistency Checks
Record Count Check
This needs to be a test we conduct though the development and maintenance of the extraction job. We need to reconsile the total count of records in the source matches the sum of new, updated, and deleted records in the target after each load.
- Many of the analytics systems do not enforce “Primary Key Uniqueness Checks”. We would need to perform them manually. I recommend so this to be part of a monitoring job and this ensures that there are no duplicates. It is a simple query but never validated.
SELECT id, COUNT(*) FROM source_table GROUP BY id HAVING COUNT(*) > 1;
Primary Key Source and Target Consistency Check
Develop a query to verify that all primary keys in the source table are present in the target table and vice versa. An important tool to check for missing Primary Keys.
SELECT id FROM landing_db.source_table WHERE id NOT IN (SELECT id FROM stagingdb.target_table);
SELECT id FROM landing_db.target_table WHERE id NOT IN (SELECT id FROM stagingdb.source_table);
Delta Verification Check
If we have implemented a diff query because we did not have a timestamp audit column, we would need to develop a query to ensure that the changes captured by the diff query accurately reflect the actual changes. Create a manual verification sample ensure that the sample
SELECT id FROM manual_verification_sample WHERE id NOT IN (SELECT id FROM canges_table);
Referential Integrity Check
We can tend miss rows because or batch window bugs. So we would need to ensure that all foreign key references in the target table are valid and available. Another check which needs to run through the pipeline lifecyle so that there are not orphan rows.
SELECT fk_id FROM target_table WHERE fk_id NOT IN (SELECT pk_id FROM referenced_table);
Column Value Check
When we combine data from multiple application system sources there are situations where need to perform checks at a column level to ensure data formats and contraints like non-null values are validaed. These requirements checks need to performed as soo as data is captured to ensure they are handled early.
SELECT id FROM source_table WHERE col1 IS NULL OR col2 IS NULL;
Very import recommendations
- Use ETL tools or scripts if possible. Dont build this. These typically support legacy applications and the solutions which we would build may only be temporary.
- The AMS Team needs to continuously monitor the process to ensure it is working correctly and efficiently. Establish month audits and have validation queries to ensure counts and values are correct.
- Document the entire process, including the logic used for diff queries and any assumptions made.
- Embed consistency checks into the ETL pipelines to catch issues early in the data integration process. Use tools such as DBT to automate consistency checks and constantly keep testing. The Data Architect is required to regularly review consistency checks performed by the data engineers adn ensuure to adapt to changes in the source or target systems and business requirements.