
Iceberg on AWS: Part 2 - Glue 4 Loves Iceberg
Lakehouse, Glue, 2024
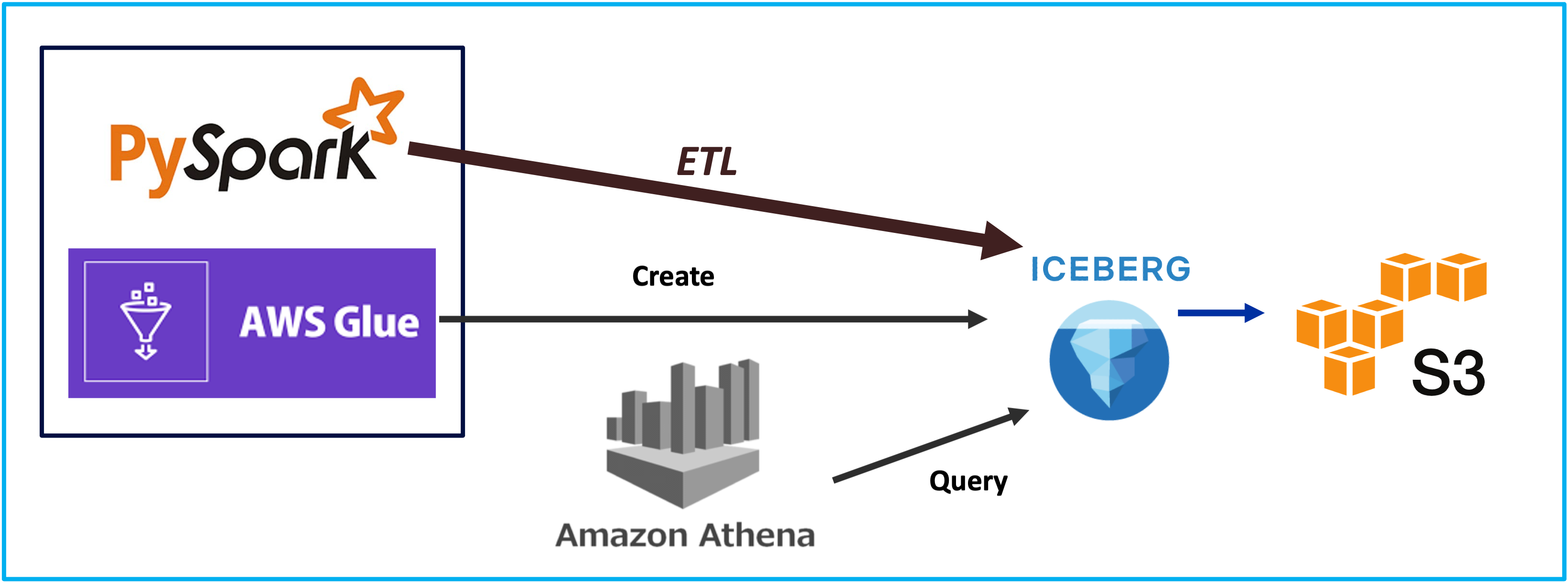
I remember trying to work with Iceberg with Glue 3 and finding it difficult to getting it to work. Glue 4 loves Iceberg.
Major Takeaways:
The advantage of using Iceberg in AWS is its integration with other services. Using Athena to manage the Iceberg tables is a natural usecase as there more folks are used to SQL to difine and manage tables. There is an added bonus of automatic integration with the Glue Data Catalog.
The pipeline can be used to integrate to both Iceberg and non iceberg datasource.
Key Configuration
There are only 2 config changes which are to be made to enable Iceberg for AWS Glue,
Specify iceberg as a value for the --datalake-formats job parameter.
Create a key named --conf for your AWS Glue job, and set it to the following value.
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
--conf spark.sql.catalog.glue_catalog=org.apache.iceberg.spark.SparkCatalog
--conf spark.sql.catalog.glue_catalog.warehouse=s3://<your-warehouse-dir>/
--conf spark.sql.catalog.glue_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog
--conf spark.sql.catalog.glue_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO
NOTE: I have never able to get the notebook working. It would been a nice to have but not a roadblock.
Objectives of this demo: Ingest data from S3 into Iceberg table which is managed by Athena. I have already created a table in Athena: Refer . Focus is on the setup.
Setup
1. Target Iceberg Lakehouse Table
This is the table which will be managed by Athena.
1.1. Create storage for the entity (table) in the lakehouse: s3://com-kfn-lakehouse-s3storage-play-erp/warehouse/ The warehouse folder will hold multiple entities and iceberg will manage employee entity inside the employee folder.
1.2. Create a Database: Name: com_kfn_lakehouse_iceberg_play_erp
1.3. Create the Iceberg Table Using Athena. Defining the table using Athena
Note: This is a schema which is not ideal but is done intentionally so that it can be tuned to demonstrate Iceberg features later.
Create table iceberg_employee
(
EMPLOYEEID string,
NAME_FIRST string,
NAME_MIDDLE string,
NAME_LAST string,
NAME_INITIALS string,
SEX string,
LANGUAGE string,
PHONENUMBER string,
EMAILADDRESS string,
LOGINNAME string,
ADDRESSID string,
VALIDITY_STARTDATE string,
VALIDITY_ENDDATE string )
location 's3://com-kfn-lakehouse-s3storage-play-erp/warehouse/iceberg_employee/'
tblproperties (
'table_type' = 'ICEBERG',
'format' = 'parquet'
);
Iceberg creates a metadata foler.
2. Landing Zone to ingest Data :
This will simulate a simple landing zone. Employee data as a csv will be the source to the pipeline: s3://com-kfn-landing-s3storage-play-erp/employee/
Configure Glue ETL job script
Using the default values as much possible to keep things simple.
Glue Studio; Author code with a script editor; Engine Spark ; Start fresh script ; Name: com-kfn-etl-glue-play-erp-employee
**Job Details**
under the job parameters add. The only change would be the location where the entity is.: warehouse=s3://com-kfn-lakehouse-s3storage-play-erp/warehouse/ This means that the Spark will look for entities within this warehouse folder structure.
--conf = spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.glue_catalog=org.apache.iceberg.spark.SparkCatalog --conf spark.sql.catalog.glue_catalog.warehouse=s3://com-kfn-lakehouse-s3storage-play-erp/warehouse/ --conf spark.sql.catalog.glue_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog --conf spark.sql.catalog.glue_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO
--datalake-formats = iceberg
Script
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# The above is boilerplat code to set up the spark script. Setting the header as true.
# Glue reads as a dynamic data frame which needs to be converted to a dataframe
inputS3DF = glueContext.create_dynamic_frame_from_options(
connection_type = "s3",
connection_options = {"paths": ["s3://com-kfn-landing-s3storage-play-erp/employee/"]},
format = "csv",
format_options={
"withHeader": True,
# "optimizePerformance": True,
})
# converting to a normal dataframe
inputS3DF = inputS3DF.toDF();
# The Glue Context is able to recognize that that the below table belongs to the iceberg configured within the --conf parameter and will manage it as a iceberg table.
# The dataframe is written to the employee iceberg table.
glueContext.write_data_frame.from_catalog(
frame = inputS3DF,
database = "com_kfn_lakehouse_iceberg_play_erp",
table_name = "iceberg_employee")
## Now read the Data from the table and store into S3
additional_options = {}
df = glueContext.create_data_frame.from_catalog(
database="com_kfn_lakehouse_iceberg_play_erp",
table_name="iceberg_employee",
additional_options=additional_options
)
# now read and load back into s3
# Convert DataFrame to DynamicFrame
dynamic_frame = DynamicFrame.fromDF(df, glueContext, "dynamic_frame_name")
glueContext.write_dynamic_frame.from_options(
frame=dynamic_frame,
connection_type="s3",
format="csv",
connection_options={
"path": "s3://kfn-study-inputdata/EmployeesAgAIN.csv",
}
)
job.commit()
Job Run
The first time the job failed. The logs clearly showed that the error was due to the fact there were no files and thus no records to load at the target
The second run was successful after uploading the source data.
Validating
Checking the rows via Athena
Checking the folder which is managed by Iceberg
A folder /data was created and the parquet files are inside it.
Ending Note: Though the documentation was and was not clear, at the end we puled through.
Sarksql query
This is using Spark Classes based integration rather thant the Glue Classes
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
df = spark.sql(
"""
SELECT * from glue_catalog.com_kfn_lakehouse_iceberg_play_erp.iceberg_employee
"""
)
# now read and load back into s3
# Convert DataFrame to DynamicFrame
dynamic_frame = DynamicFrame.fromDF(df, glueContext, "dynamic_frame_name")
glueContext.write_dynamic_frame.from_options(
frame=dynamic_frame,
connection_type="s3",
format="csv",
connection_options={
"path": "s3://kfn-study-inputdata/EmployeesMix.csv",
}
)
job.commit()