
Curate: Data Cleansing
Published in Processing, 2024
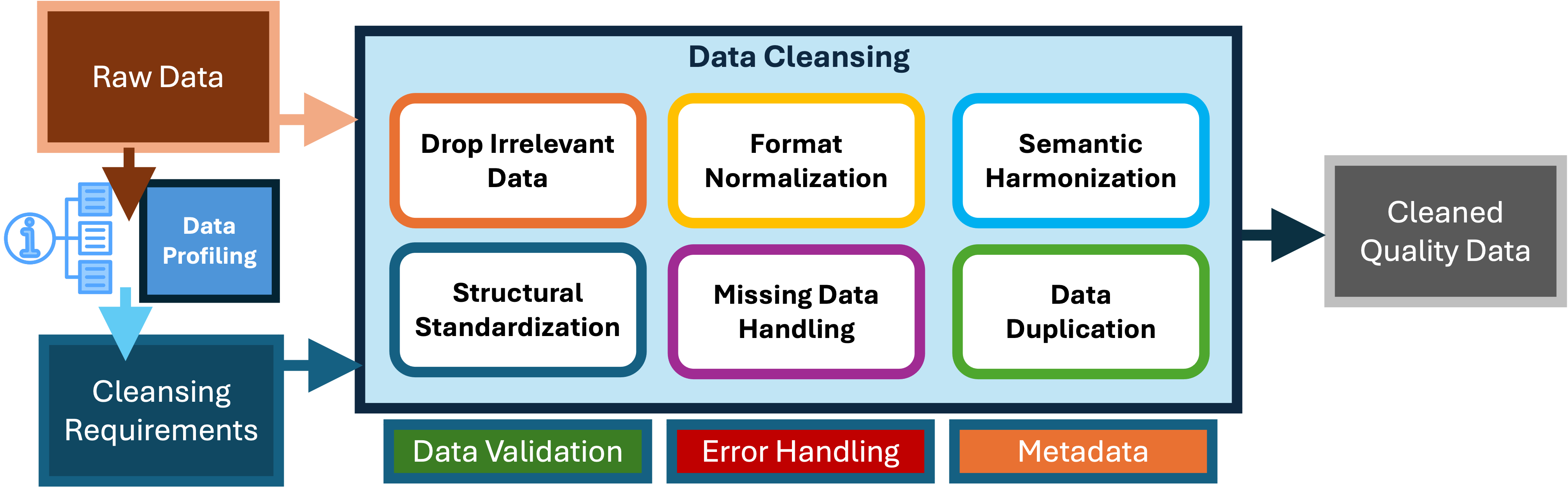
Data Cleansing
I have seperate page on Data Profiling the source data in the context of processing the data for analytics.
1. Drop Irrelevant Data
It is important to process only the data that is useful for analytics. If there are columns that are not beneficial—either because they are sparse or lack semantic value (e.g., technical data that does not help in understanding or interpreting the data)—they should be removed. Irrelevant data introduces noise, making it harder to extract meaningful insights. By eliminating unnecessary data, you ensure that your analysis focuses on information that is pertinent to the business problem or research question.
CASE STUDY: I once asked a team to quickly assess the data quality within a data warehouse. The team initially said the task was impossible because the main tables had around 1,000 columns, making it too time-consuming to analyze. However, a data analyst remarked that many of the columns were not used. After a quick investigation, we realized that more than 70% of the columns were not important to the business but were still being processed into the data warehouse, which was plagued with quality issues. We narrowed our focus to 150 key columns, which allowed us to improve data quality by 400% and, most importantly, increase the credibility of the reports.
Removing irrelevant data during the cleansing process is vital for maintaining high data quality, improving analytical performance, and ensuring that insights are accurate and meaningful. It enhances efficiency, simplifies data management, and contributes to better model performance, clearer reporting, and stronger data governance. By eliminating unnecessary noise, the focus remains on the most important and actionable information, leading to more effective and reliable analytics processes.
Profile Data and Define Relevance Criteria: As part of the data profiling step, analyze the source data to flag data that is incomplete or of low quality, as it might be irrelevant or harmful to the analysis. Use the results of data profiling to work with stakeholders to understand the business context and identify the specific data elements that are unnecessary for decision-making. Develop criteria or rules that determine what constitutes relevant versus irrelevant data. These rules can be based on factors such as data attributes, business logic, timeframes, or specific use cases.
Whether you decide to remove columns entirely or filter out rows, these decisions need to be documented, published, and continuously reviewed.
2. Format Normalization
It is important to convert individual data elements into a consistent and standardized format. Format Normalization is key to accelerate development velocity and quality code. We would need to convert data into a common format (e.g., dates to a standard format, converting all text to lowercase). In this step we need to ensure that the data types are consistent and correct any discrepancies.
This also includes *data type conversions to appropriate types (e.g., string to date, float to integer). Below are common examples. This involves ensuring that all data entries follow the same formatting rules, such as date formats, phone numbers, text case (e.g., upper case vs. lower case), and address formatting. The main goal is to eliminate inconsistencies in how data is represented, making it easier to process, search, and analyze. It also ensures that data can be easily integrated with other systems or datasets that may require specific formats.
Apply Proper Precision and Scale
For numeric fields, ensure the correct precision and scale are applied (e.g., using DECIMAL(10,2) for currency values). I have seen numerals as strings many times which is not accepted. Also know what are integers vs floats etc. I am using the example from Parquet: Modifying float64 to float32 as it would suffice for the values we would need.
index = pyar.Schema.get_field_index(myschema, 'TAXAMOUNT')
myschema = pyar.Schema.set(myschema, index, pyar.field('TAXAMOUNT', pyar.float32()))
index = pyar.Schema.get_field_index(myschema, 'NETAMOUNT')
myschema = pyar.Schema.set(myschema, index, pyar.field('NETAMOUNT', pyar.float32()))
index = pyar.Schema.get_field_index(myschema, 'GROSSAMOUNT')
myschema = pyar.Schema.set(myschema, index, pyar.field('GROSSAMOUNT', pyar.int32()))
print(f"the new updated schema -> abover 3 columns would be updated to float from double")
print('----------------------------------------------------------------------------------------------------------')
updateParquetAndMetaData(df_salesOrder, myschema)
the new updated schema -> abover 3 columns would be updated to float from double
----------------------------------------------------------------------------------------------------------
SALESORDERID: int64,CREATEDBY: int64,CREATEDAT: date32[day],CHANGEDBY: int64,CHANGEDAT: date32[day],FISCVARIANT: string,FISCALYEARPERIOD: int64,PARTNERID: int64,SALESORG: string,CURRENCY: string,GROSSAMOUNT: int32,NETAMOUNT: float,TAXAMOUNT: float,LIFECYCLESTATUS: string,BILLINGSTATUS: string,DELIVERYSTATUS: string
Column Data Type Conversion
Changing data type is one of the most common column transformations. Ensure that similar date fields across different tables or datasets use the same data type (e.g., use DATE or TIMESTAMP consistently for date fields).
as VALIDITY_STARTDATE
Consistent Casing and Spacing
Another common text processing on columns is converting text data to a consistent case (e.g., all lowercase or all uppercase). Trimming leading, trailing, or excessive in-between spaces.
String Transformations
Perform operations like trimming, padding, and case conversion.
UPPER(CITY) AS CITY
initcap(full_name) as normalized_name
Trimming Column Text: Medium Descito
TRIM()
Normalize phone numbers to the format ‘+1-XXX-XXX-XXXX’
regexp_replace(phone_number, '^(\d{3})(\d{3})(\d{4})$', '+1-\1-\2-\3') as normalized_phone_number,
3. Semantic Harmonization
We need to ensure data is consistent in meaning and interpretation across different systems, datasets, or contexts. For example we need to ensure that “NY,” “N.Y.,” and “New York” all refer to the same entity. This includes reference data and terms such as “client,” “customer,” and “consumer” are used consistently across datasets or are mapped to a single, standardized term. Essentially tt involves aligning data values and terminology to a common set of definitions, categories, or standards.
Column Transformation
Very often we are required to parsing column text (Strings) to splitting or extracting parts of data (e.g., extracting domain from email, splitting full name into first and last names). Also we often would need to combine or merge text from multiple columns to into a single. This will include simple String split based on a char or a regex expression.
Column Merging
Combine multiple columns into one. I once had to combine columns for a text processing usecase.
CONCAT_WS(' ', NAME_FIRST, NAME_MIDDLE, NAME_LAST, NAME_INITIALS) as full_name
Regular Expression Transformations
Use expressions on string values
REGEXP_SUBSTR(
REGEXP_REPLACE
( WEBADDRESS, 'https?://|www\.|/$', ''), '^[^/]+') AS EXTRACTED_DOMAIN
Column Splitting
Split a column into multiple columns based on a delimiter.
SPLIT_PART(EMAILADDRESS, '@', 2) AS EMAILDOMAIN
New Column Imputation
Derive and create a new columns based on existing data to either improve on the existing column.
Derivation
Date and Time Transformations by extracting parts of dates, convert time zones, or format dates.
CAST(SUBSTRING(CAST(FISCALYEARPERIOD AS STRING), 1, 4) AS INTEGER) AS FISCALYEAR,
CAST(SUBSTRING(CAST(FISCALYEARPERIOD AS STRING), 5, 3) AS INTEGER) AS FISCALMONTH,
CASE
WHEN CAST(SUBSTRING(CAST(FISCALYEARPERIOD AS STRING), 5, 3) AS INTEGER) IN (1, 2, 3) THEN 1
WHEN CAST(SUBSTRING(CAST(FISCALYEARPERIOD AS STRING), 5, 3) AS INTEGER) IN (4, 5, 6) THEN 2
WHEN CAST(SUBSTRING(CAST(FISCALYEARPERIOD AS STRING), 5, 3) AS INTEGER) IN (7, 8, 9) THEN 3
ELSE 4
END AS FISCALQUARTER
Conditional Transformations
Apply transformations based on conditions.
CASE
WHEN ADDRESSTYPE = 1 THEN 'BILL'
WHEN ADDRESSTYPE = 2 THEN 'SHIP'
ELSE CAST(ADDRESSTYPE AS STRING)
END AS ADDRESSTYPE_TRANSFORMED
Address formating
Converting addresses to a standard format (STREET, CITY, STATE, ZIPCODE, COUNTRY etc based on the enterprise standard. I have also converted addresses to geographic coordinates (latitude and longitude) using external APIs.
Error Correction
Correcting known errors in data (e.g., fixing typos, correcting known incorrect values).
Outlier Handling
Identifying and handling outliers (e.g., reviewing and correcting, flagging, or removing).
Perform Data Integrity Checks
Perform Referential Integrity checks by running queries to confirm that the relationships between tables are maintained (e.g., foreign key constraints). If there are unique constraints which are required we would need perform a checks to ensure that specific columns contain unique values (e.g., email addresses, primary keys).
Data Masking:
Anonymization: Masking or anonymizing sensitive data (e.g., replacing names with pseudonyms, masking credit card numbers). Redaction: Removing or hiding sensitive data (e.g., removing social security numbers).
Aggregating: Summarizing or aggregating data (e.g., total sales per month). Joining: Merging data from multiple sources or tables (e.g., joining customer data with order data)
4. Structural Standardization
Renaming Columns
Change column names for consistency or clarity.
LOGINNAME as USERNAME
Handling Missing Values
Use Nullable Types When Appropriate: If a field can have null values, ensure that the data type allows nulls (e.g., using Nullable
Fill, drop, or impute missing values
coalesce(NAME_FIRST, '') as NAME_FIRST
PENDING Augmentation: Adding additional data from external sources to enrich the dataset (e.g., appending geographic information based on IP addresses).
Column Value Imputation
Imputing a column value of Short Description from Medium Desc column only when the Medium Desc column is not null.
CASE
WHEN MEDIUM_DESCR IS NOT NULL THEN
ELSE
END AS DESCRIPTION
5. Data Deduplication
Have continous validation to identify duplicate records using various techniques. Combining duplicate records into a single record or deleting redundant duplicate records.