
Solve technical problems, increase efficiency and productivity, and improve systems
We need repeatable processes and patterns for designing, building, and maintaining systems that enable the architecture to collect, store, and process large volumes of data. These data pipelines must ensure that data is accessible, reliable, and efficiently available for analysis and decision-making. My goal is to demonstrate how tools and technologies can implement these processes and patterns throughout the data lifecycle, from source to destination, while maintaining quality, scalability, and security.10 Terraform best practices - Simple enough and all projects need to include
Infrastructure as code, Teraform, Azure, Teraform
Iceberg on AWS: Part 3 - Glue Spark Evolves Schema
Lakehouse, Glue Spark, Iceberg, AWS
Column Transformations for Staging
Lakehouse, DBT, Snowflake, AWS
Slowly Changing Dimensions - Type 2 with Glue, Pyspark and Iceberg
Data Modeling, SCD2, AWS
Incremental (Append and Deduplicate) Load with Airbyte Demo
, Delta, Airbyte
Incremental Append Only Load with Airbyte Demo
, Delta, Airbyte
Parquet: Best practices demonstration
A often overlooked feature of Parquet is its support for Interoperability which is key to enterprise data plaforms which serves different tools and systems, facilitating data exchange and integration. This is my take on Parquet best practices and I have used python-pyarrow to demonstrate them.
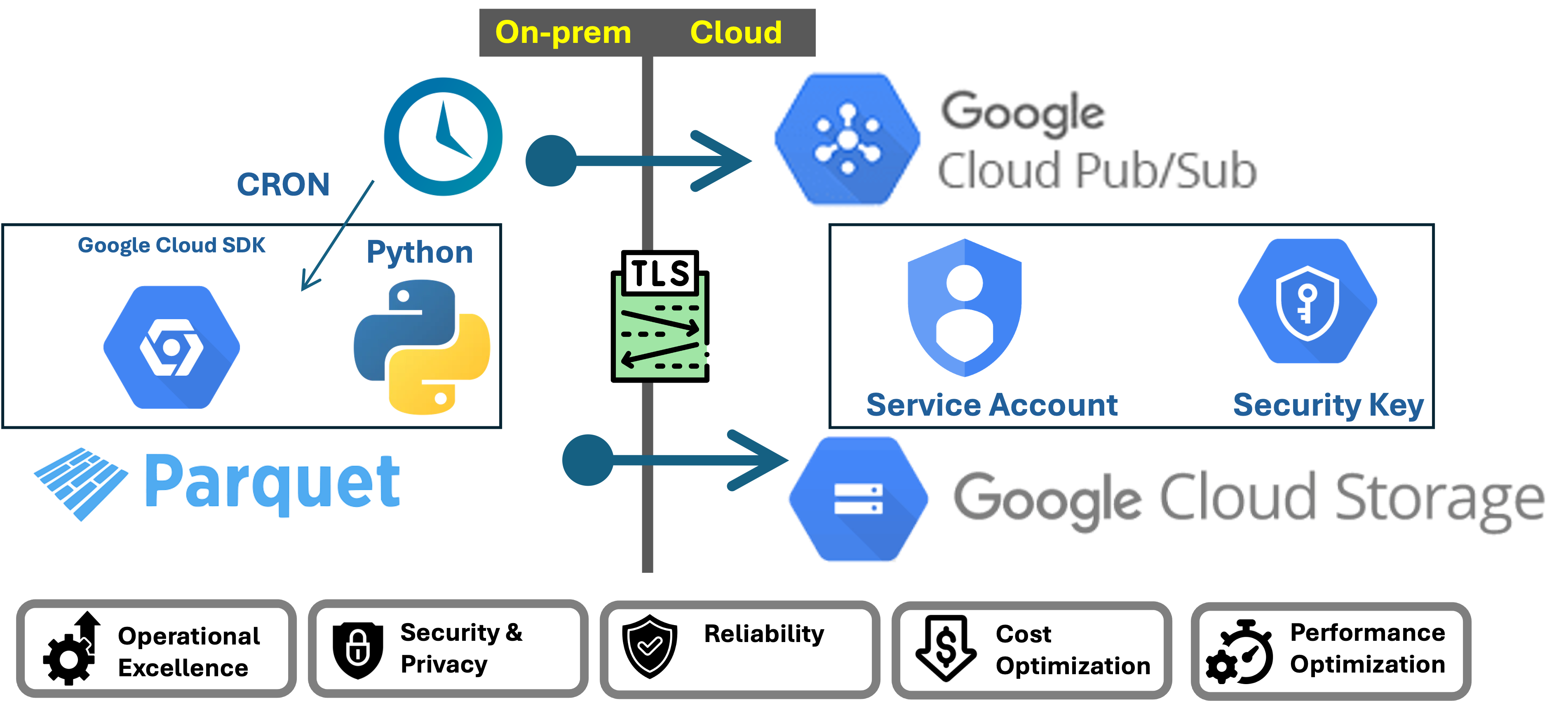
Cloud Storage: Best practices
- Buckets names: I am split on wheter to have have smart names which clear inform about the intent of the bucket and its files and the security concerns that may arise by doing so. If there is a need to hide the intent of buckets from possible attackers, we would need manage and enforce catalogs. However, I have seen the worst of both worlds in which the naming is gives enough and these buckets not being cataloged. I would recommend a naming coventions or rules to catalog bucket names and have audits to ensure compliance.
Snowflake Implementation Notes
Virtual Warehouses
Data Engineering Project Initiation Checklist
Some upfront work is required to ensure the success of data engineering projects. I have used this checklist to provide a framework for collaborating with multiple stakeholders to define clear requirements and designs.