
What is usable data
For data to be usable for analytics purposes, we need it to have an acceptable quality, readily available and easily accessible.

Discoverable
But for data consumers who are not savvy with to interact with the data, we would need to go even further to make it usable. I appreaciate Data Mesh for articulating just that. They start with data needing to be Discoverable. Essentially, users would need to centralized regitry (catalog) where they can browse what data is available with enough information about the dataset for them to know if it would be applicable to their needs.
We can imagine multiple interesting information which can be provided to the user for them to assess if the data meets their needs such as sample dataset, context of the business it would be applicable. For example, a customer 360-degree view data can provides all the aspects of the customer which are avaible within the dataset such as contact information, purchase history, and support interactions. We categorize this data which we provide to the users as Descriptive (or business) Metadata and includes information on title, purpose, business intent, creation date, creator, key entity definitions, detailed descriptions of important relationships between entities and rules that govern those relationships from a business perspective. Typically we would include classification data covering security, privacy (public, private, restricted or regulatory classifications such as PII).
Data stewards or business SMEs who can speak the language consumers can relate to are typically the ones who provides this data (metadata) which support the disoverability of the data within a catalog. There are a few standards such as Dublin Core and MARC. Most mordern data catalog tools support this level of metdadata.
Understandable
Once the user is able to know that the data which they have disovered to support their business needs, we would need to provide further information to the users for them to understand the data so that they can interact with it. We typicall would provide Structural Metadata to understand the schema of the dataset, how data is formatted, with information on tables, views, entity types, and relationships.
It can additional provide information to the users to understand how data can be organized and providing guidance on how the data can be combined with other data with links to types of queries that can be executed on the datasets, code snippets, demonstractions on the data, comments from other users and major usecases where the datasets have been used
Before I go any further there is a great online resource which publishes the FAIR principles for data. “provides guidelines to improve the Findability, Accessibility, Interoperability, and Reuse of digital assets. The principles emphasise machine-actionability (i.e., the capacity of computational systems to find, access, interoperate, and reuse data with none or minimal human intervention) because humans increasingly rely on computational support to deal with data as a result of the increase in volume, complexity, and creation speed of data.”
Findable
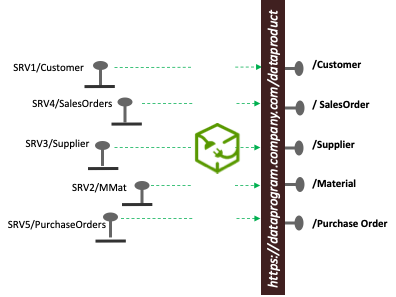
Data Mesh refers to Findability as Addressable. As indicated by FAIR Principles, providing Globally unique and persistent identifiers is arguably the most important aspect of ensuring data is findable. I have used URI URL API endpoints which rerouted requests to where the data is is actually sourced as the standard as the address of published datasets. In the below example, Sales order datasets are sourced from a service SRV4/SalesOrders but are actually uniquely and persistently addressed from https://dataprogram.company.com/dataproduct/SalesOrders. Even if the sourcing system changes, the API endpoint which routes would persist.
Assessable
Once users finds the required data, they would need to know how they can be accessed, possibly including authentication and authorisation. There are multiple types of consumers (Data Sceintists, Data Analysts, Business SMEs, Data Integrators etc) and this is where we would need to know consumption patterns. Administrative metadata which includes access permissions, locations, data type, file name and size, ownership information (for access approval), access protocols etc support users on how to access the data.
Acceptable Quality for Data Including Datasets and Datasources
The main Data Quality Issues which plague data and drastically reduce the usability of data is
- Data Duplication
- Referential Integrity Issues
- Missing Data (Completeness)
- Non Standard Data
- Inaccurate Data
- General availability
- Performance
- Timeliness (Refresh delays causing stale data)
From my experience data quality needs to be addressed as projects just like automation is addressed. Addressing DQ at an enterprise level is difficult because of sponsorship. Just as organization built a culture and awareness around automation, we need to build an awareness around data quality and federate sponsorship of these data quality issues by funding them just like IT automation projects with ROI and KPI measures and build a development lifecycle with requirements and concrete objectives.
Data mesh formalizes a framework to provide guarantees on the quality of data using service-level objectives (SLOs)—objective on datasets which are published as products.
Interoperable
In the Integrated data page, we highlighted the necessity of integrating data for it to be useful in analytics. This can be achieved through either physical or logical data integration.
Beyond integration, it is essential to enable data to be transferred from its source system to other applications and workflow systems that are logically and physically separate. This data should seamlessly integrate with the resident data within the new system. This capability, where data can integrate seamlessly with external applications or workflows, is referred to as interoperable data.
I have worked extensively on this problem, and the way I see it, achieving this capability involves building on how we integrate data and scale data linking across multiple disparate applications. For instance, we need unique identifiers that are globally applicable across the enterprise. For this to work effectively, file and data formats should adhere to open standards, making them usable in other systems. Additionally, schemas should be designed to link outside the analytics systems for which they were originally defined.
Secure
All the above capabilities push for democratization of data, making it easier for data to be consumed and leveraged to improve business productivity and decision-making. Security ensures that this is done in a safe and compliant way.