
Data Strategy and architecture in practice
, Home, 2024
Foundation: Explaining things simply is crucial
I believe that the simpler I can explain things, the more intimate I am with the topic. The better I explain a topic to someone unfamiliar with it, the better I understand it myself. Simple explanations ensure the message is clear and easily understood by a wider audience. Ideas need acceptance from large audiences within the organization to become reality. By simplifying explanations, we make ideas accessible to people with varying expertise, encouraging engagement. This avoids confusion, saves time, and promotes quicker comprehension and decision-making. Simple explanations also help uncover flaws, improve concepts, and aid retention, fostering innovation. This foundation allows for deeper concepts to be built upon.
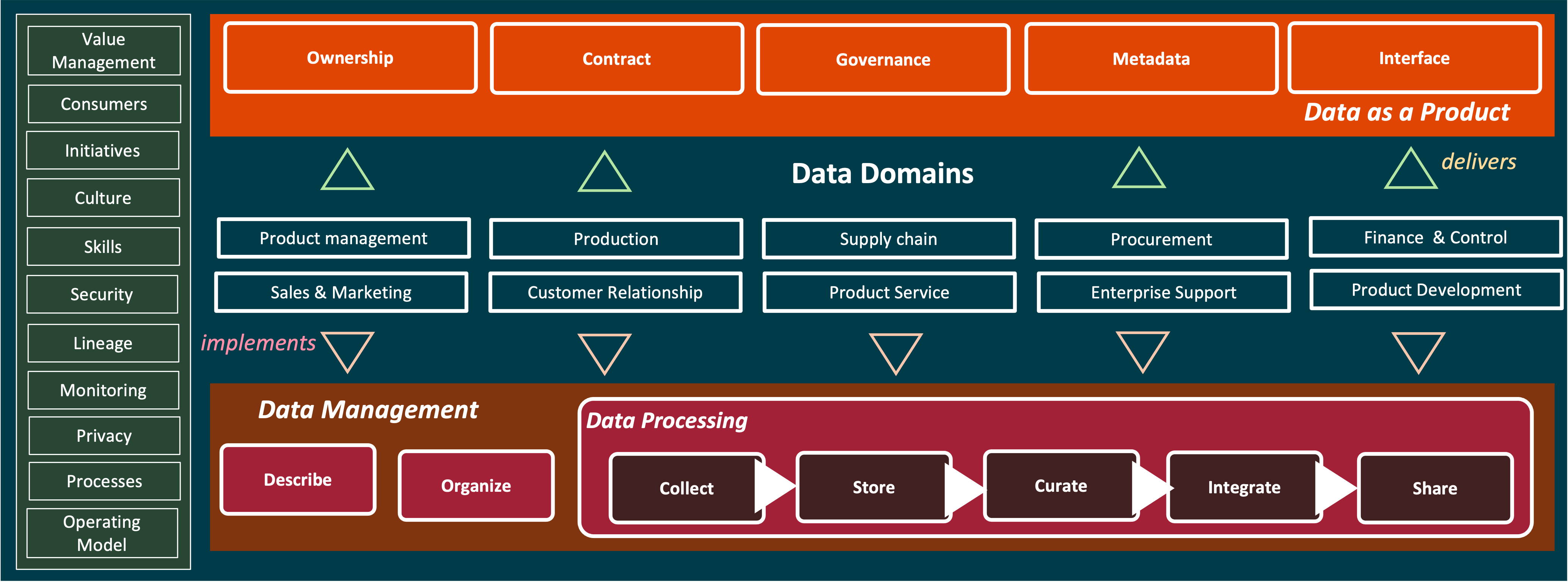
Architecture: How do we manage our data
In the foundation section, I defined a high-level aspirational vision of the data analytics capabilities required to deliver business value. Now, we need frameworks and solution concepts that can consistently deliver these capabilities. It is important to consider various factors that influence how data analytics solutions are designed and implemented.
The architecture needs to consider each of these elements
- assumptions - These are conditions believed to be true for the architecture but have not yet been validated.
- constraints - These are limitations that must be adhered to, such as budget, time, technology, or legal restrictions.
- domain-specific principles - These are guiding principles specific to the domain that influence how the architecture is developed.
- policies & standards - These are established norms, specifications, and rules that the architecture must comply with.
Engineering
We need repeatable processes and patterns for designing, building, and maintaining systems that enable the architecture to collect, store, and process large volumes of data. These data pipelines must ensure that data is accessible, reliable, and efficiently available for analysis and decision-making. My goal is to demonstrate how tools and technologies can implement these processes and patterns throughout the data lifecycle, from source to destination, while maintaining quality, scalability, and security.
Sandbox: Setting up tools
Credibility is key to any architect or data leader. This credibility needs to be earned by gaining knowledge of technology not by reading a sales pitch but by experiencing the technology.
I often find myself lost in my day-to-day deliverables and have difficulty keeping up with evolving tools, especially as data technologies evolve rapidly. Sure, I can look at a demo, but I can truly understand something only when I touch, feel, and experience it. Being able to quickly prototype and test solutions goes a long way in building a concept which I can then build upon and conceptualize how I can fit it into a larger architecture.
Hands-on knowledge of technology is important to me to ensure that I can design practical, scalable, and efficient data architectures. It enhances my ability to communicate with technical teams, ensures the quality and performance of solutions, and fosters continuous improvement and innovation. It makes it easier to identify potential issues and bottlenecks in the architecture early in the design and implementation phases.
I have seen so many bad decisions made because leaders do not understand the technology constraints and opportunities. By setting up a sandbox and piloting a quick demo to highlight the capabilities of a technology and how they align with the data architecture and strategy, we can better translate business requirements into technical solutions that are realistic and achievable.
From personal experience, hands-on knowledge allows me to build rapport with data engineers and developers who I have to lead. They are more likely to trust and follow the guidance of someone who understands the intricacies of the work. At the same time, it also helps to understand complexity and review the true progress of the development team.
Patent
Background: For Boeing to realize its strategy of expanding to a global workforce, exporting technology data across their engineers and suppliers needs to be tightly controlled by complex license EAR and ITAR agreements with the US government. These license agreements are legal documents which detail what technology data can be exported to which country, organization/individual and under what conditions. These agreements need to be manually read by Boeing’s Global Trade Controls to determine export, which comes with long delays. Automation of extracting the rules and conditions from the documents would reduce these inefficiencies.
Technology Challenge: The license agreement which are PDF text or images are a combination of semi structured and full text legal language with multiple document sections dependent on each other. Features or data attributes needed to be extracted from these documents with high accuracy, to build out rules under which technology data can be exported. There was no tool or technology which was available to handle this complexity.
I was responsible to pilot Boeing’s machine learning platform, led a team to build and engineer the solution and finally establish confidence from compliance organization on the viability of the solution. Additionally I have a patent on the solution provided. Patent Summary: A method for training a filter-based text recognition system for cataloging image portions associated with files using text from the image portions, the method comprising: receiving a first set of text represented in a first image portion associated with a first file; classifying the first image portion into a predetermined group, where in the classifying is based at least in part on the first set of text; extracting a first set of features from the first set of text; harmonizing existing data in the predetermined group with the first set of text to modify the first set of features; categorizing the first set of text; and determining analytics-based rules based at least in part on the first set of features.